Remote Procedure Calls
Introduction
Paul Krzyzanowski
September 17, 2023
Goal: Provide a layer of abstraction for process-to-process communication that enables a process on one system to invoke a function, or service, on a another system without having to deal with the problems of formatting data and parsing the request.
Introduction
Sockets are a fundamental part of client-server networking. They provide a relatively easy mechanism for a program to establish a connection to another program, either on a remote or local machine and send messages back and forth (we can even use read and write system calls). This interface, however, forces us to design our distributed applications using a read/write (send-receive) interface which is not how we generally design non-distributed applications. In designing centralized applications, the procedure call is usually the standard interface model, allowing for the creation of components that have functional interfaces. If we want to make distributed computing look like centralized computing, input/output-based communications is not the way to accomplish this.
In 1984, Birrell and Nelson devised a mechanism to allow programs to call procedures on other machines. A process on machine A can call a procedure on machine B. When it does so, the process on A is suspended and execution continues on B. When B returns, the return value is passed to A and A continues execution. This mechanism is called the Remote Procedure Call (RPC). To the programmer, it appears as if a normal procedure call is taking place. Obviously, a remote procedure call is different from a local one in the underlying implementation.
Steps in a remote procedure call
Consider how local procedure calls are implemented. This differs among compilers and architectures, so we will generalize. Every processor provides us with some form of call instruction, which pushes the address of the next instruction on the stack and transfers control to the address specified by the call. When the called procedure is done, it issues a return instruction, which pops the address from the top of the stack and transfers control there. That’s just the basic processor mechanism that makes it easy to implement procedure calls. The actual details of identifying the parameters, placing them on the stack, and executing a call instruction are up to the compiler. The compiler generates code to evaluate each parameter, push its value on the stack, and then issue the call to the function. In the called function, the compiler is responsible for generating code to ensure that any registers that may be clobbered are saved, allocating stack space for local variables, and then restoring the registers and stack pointer prior to a return.
None of this makes sense if we want to call a procedure that is loaded on a remote machine. This means that the compiler has to do something different to provide the illusion of calling a remote procedure.
Remote procedure calls are a programming language construct. They are implemented by the compiler or interpreter of the programming language as opposed sockets, which is an operating system construct since it is a facility provided by the operating system. They provide the illusion of calling a procedure on a remote machine. During this time, execution of the local thread stops until the results are returned. The programmer is alleviated from packaging data, sending and receiving messages, and parsing results.
The illusion of a remote procedure call is accomplished by generating stub functions. On the client side, the stub (often called a proxy) is a function with the same interface as the desired remote procedure. Its job is to take the parameters, marshal them into a network message, send them to the server, await a reply, and then unmarshal the results and return them to the caller. On the server side, the stub (often known as a skeleton) is responsible for being the main program that registers the service and awaits incoming requests for running the remote procedure. It unmarshals the data in the request, calls the user’s procedure, and marshals the results into a network message that is sent back to the recipient.

The client calls a local procedure, called the client stub. To the client process, this appears to be the actual procedure, because it is a regular local procedure. It just does something different since the real procedure is on the server. The client stub packages the parameters to the remote procedure (this may involve converting them to a standard format) and builds one or more network messages. The packaging of arguments into a network message is called marshalling and requires serializing all the data elements into a flat array-of-bytes format.
Network messages are sent by the client stub to the remote system (via a system call to the local kernel using sockets interfaces).
Network messages are transferred by the kernel to the remote system via some protocol (either connectionless or connection-oriented).
A server stub, sometimes called the skeleton, receives the messages on the server. It unmarshals the arguments from the messages and, if necessary, converts them from a standard network format into a machine-specific form.
The server stub calls the server function (which, to the client, is the remote procedure), passing it the arguments that it received from the client.
When the server function is finished, it returns to the server stub with its return values.
The server stub converts the return values, if necessary, and marshals them into one or more network messages to send to the client stub.
Messages get sent back across the network to the client stub.
The client stub reads the messages from the local kernel.
The client stub then returns the results to the client function, converting them from the network representation to a local one if necessary.
The client code then continues its execution.
The major benefits of RPC are twofold. First, the programmer can now use procedure call semantics to invoke remote functions and get responses. Secondly, writing distributed applications is simplified because RPC hides all of the network code into stub functions. Application programs don’t have to worry about details such as sockets, port numbers, and data conversion and parsing. On the OSI reference model, RPC spans both the session and presentation layers (layers five and six).
Challenges in implementing RPC
There are a few hurdles to overcome in implementing remote procedure calls:
- Parameter passing
- Most parameters in our programs are passed by value. That is easy to do remotely: just send the data in a network message. Some parameters, however, are passed by reference. A reference is a memory address of the parameter. The problem with passing this is that memory is local and the memory address passed from a client to a server will now refer to memory on the server rather than to the contents on the client. There is no good solution to this except to understand the data that is being referenced, send it to the remote side (pass by value), where it will be placed in some temporary memory. A local reference can then be passed to the server function. Because the contents might have been modified by the function, the data will need to be sent back to the calling client and copied back to its original location.
- Marshalling
- All data that is sent needs to be represented as a series of bytes that can be placed into one or more network messages. This is known as marshalling. Not only must any data structure be sent in a serialized format: a sequence of bytes with no pointers, but the format of this marshalled data must be standardized between the client and server so that the server can make sense of the data it receives and vice versa. Different processors and languages may use different conventions for integer sizes, floating point sizes and formats, placement of most significant bytes, and alignment of data.
- The marshalled data that is sent over the network may contain data that makes it self-describing: identifying the individual parameters by name and type. Such a format is known as explicit typing. JSON and XML formats are examples of this. In contrast, implicit typing does not send such information and requires the remote side to know the precise expected sequence of parameters.
- Generating stubs
- Since most languages do not support remote procedure calls natively, something has to generate client and server stubs. That is often a stand-alone program known as an RPC compiler, or protocol compiler. The RPC compiler takes an interface specification as input and generates client-side stubs (proxies) and a server-side proxy (skeleton). The interface specification is written in an interface definition language (IDL) and defines remote classes, methods, and data structures. It contains all the information that the RPC compiler needs to generate stub functions.
- Looking up services
- A client process needs to find out how to set up a network connection to an appropriate service that hosts the remote procedures: which host and port to use. An RPC name server is a network service that a client can communicate with to query the host and port of a desired remote interface. The client sends the server a name identifying the interface. That “name” is often a number that uniquely identifies the service that hosts a set of functions on the server. The server returns a host and port number for the service that implements the functions. In many cases, the name server resides on the machine where the remote procedures run and the server will return only the port number. When a service starts up, it will register its interfaces with the RPC name server.
- Handling failures
- Distributed systems must handle partial failure. We don’t have a concept of local procedure calls not working. With remote calls, however, problems can arise. The server can stop working or network connectivity may break or experience unexpected delays. These may prevent or delay requests reaching the server or responses reaching the client.
- Semantics of remote calls
- To deal with failures or delays, RPC libraries may attempt to retransmit requests if a response is not received in time. This may have the side-effect of invoking a procedure more than once if the network is slow. In some cases, no harm is done in doing this. Functions that may be run multiple times without undesirable side-effects are called idempotent functions. Functions that have undesirable side-effects if run multiple times (e.g., transfer $500 from my checking account to my savings account) are called non-idempotent functions. Most RPC systems offer at least once semantics, in which case a remote procedure will be executed one or more times (if there are network delays) or at most once semantics, in which case a remote procedure library will avoid resending the procedure request even if it does not get a timely response. Software that uses remote procedure calls has to be prepared to deal with errors that can arise from problems in contacting or getting a response from a remote procedure.
- Performance
- A regular procedure call is fast: typically only a few instruction cycles. What about a remote procedure call? Think of the extra steps involved. Just calling the client stub function and getting a return from it incurs the overhead of a procedure call. On top of that, we need to execute the code to marshal parameters, call the network routines in the OS (incurring a mode switch and a context switch), deal with network latency, have the server receive the message and switch to the server process, unmarshal parameters, call the server function, and do it all over again on the return trip. Without a doubt, a remote procedure call will be much slower. We can easily expect the overhead of making the remove call to be thousands of times slower than a local one. However, that should not deter us from using remote procedure calls since there are usually strong reasons for moving functions to the server.
- Security
- Security was never a concern with local procedure calls: all function calls are executed within the confines of one process and we expect the operating system to apply proper memory protection through per-process memory maps so that other processes are not privy to manipulating or examining function calls. All interactions with resources are based on user permissions and the entire process runs with the authority of the user. With RPC, we have to be concerned about various security issues:
Is the client sending messages to the correct remote process or is the process an impostor?
Is the client sending messages to the correct remote machine or is the remote machine an impostor?
Is the server accepting messages only from legitimate clients? Can the server identify the user at the client side?
Can the message be sniffed by other processes while it traverses the network?
Can the message be intercepted and modified by other processes while it traverses the network from client to server or server to client?
Is the protocol subject to replay attacks? That is, can a malicious host capture a message an retransmit it at a later time?
Has the message been accidentally corrupted or truncated while on the network?
Does the user’s identity exist on the remote system and can access controls be properly applied?
Programming with remote procedure calls
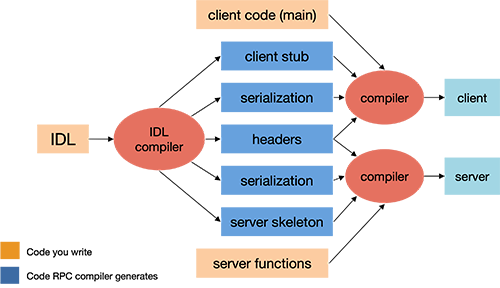
Most languages used today (C, C++, Scheme, et alia) were not designed with built-in syntax for remote procedures and are therefore incapable of generating the necessary stub functions. To enable the use of remote procedure calls, one common solution is to provide a separate compiler that generates the client and server stub functions. This compiler takes its input from a programmer-specified definition of the remote procedure call interface. Such a definition is written in an interface definition language.
The interface definition generally looks similar to function prototype declarations: it enumerates the set of functions along with input and return parameters. After the RPC compiler is run, the client and server programs can be compiled and linked with the appropriate stub functions (Figure 2). The client procedure has to be modified to initialize the RPC mechanism (e.g. locate the server and possibly establish a connection) and to handle the failure of remote procedure calls.
Even if a language has support for remote procedure calls (e.g., Java), one may still need a separate IDL compiler if there is a need to handle different RPC protocols than the one provided by the language.
Advantages of RPC
You don’t have to worry about getting a unique transport address (picking a unique port number for a socket on a machine). The server can bind to any available port and then register that port with an RPC name server. The client will contact this name server to find the the port number that corresponds to the program it needs. All this will be invisible to the programmer.
The system can be independent of transport provider. The automatically-generated server stub can make itself available over every transport provider on a system, both TCP and UDP. The client can choose dynamically and no extra programming is required since the code to send and receive messages is automatically generated.
Applications on the client only need to know one transport address: that of the name server that is responsible for telling the application where to connect for a given set of server functions.
The function-call model can be used instead of the send/receive (read/write) interface provided by sockets. Users don’t have to deal with marshalling parameters and then parsing them out on the other side.
RPC API
Implementing remote procedure calls requires various supporting services. The key components to support RPC will often include:
- Marshalling operations
- Data that goes to and from a remote procedure (arguments, return values, and exceptions) has to be converted to a format that can be transmitted over the network (serialization) and then converted that data back into its original format (deserialization) on the other end. It needs to be augmented with additional information, such as the function or method that is being called, object instance (if objects are supported), and version number (if versioning is supported). Common serialization formats in Python include XML (for XML-RPC), JSON (for JSON-RPC), and Protocol Buffers (for gRPC). The choice of serialization format can influence the speed and efficiency of the RPC communication.
- Name service and discovery operations
- Register and look up binding information (ports, machines, protocols). Allow an application to use dynamic (operating system assigned) ports.
- Transport protocol support
- Once data is serialized, it needs to be sent to the remote system. This is achieved through a transport protocol. Some systems use TCP or UDP protocols directly. Others, such as XML-RPC may use HTTP/HTTPS over TCP or, in the case of gRPC, HTTP/2 over TCP.
- Connection Management
- The system needs to handle the creation, maintenance, and termination of network connections. This can involve dealing with connection pooling, retries, timeouts, and other network-related issues.
- Service definition and stub/skeleton generation
- In some RPC frameworks, especially those using strongly-typed data structures (like gRPC), service interfaces need to be explicitly defined through an interface definition language. These definitions often provide information about the methods available, their input parameters, and their return types. Stubs (client-side proxies) and skeletons (server-side method implementations) are then auto-generated from these definitions.
- Security operations
- The system should provide mechanisms for the client and server to be able to authenticate each other and to provide a secure communication channel between the two.
- Stub memory management and garbage collection
- Stubs may need to allocate memory for storing parameters, particularly to simulate pass-by-reference semantics. The RPC package needs to allocate and clean up any such allocations. They also may need to allocate memory for creating network buffers. For RPC packages that support objects, the RPC system needs a way of keeping track whether remote clients still have references to objects or whether an object can be deleted.
- Error Handling
- Errors can occur during remote calls, both at the application level (e.g., an exception in the remote method) or at the network level (e.g., network outage, timeout). A good RPC mechanism will have robust error handling and might also support features like exception propagation.
- Object and function ID operations
- Allow the ability to pass references to remote functions or remote objects to other processes. Not all RPC systems support this.
- Security operations
- Depending on the use case, the RPC communication might need to be secured. This can involve authentication – verifying the identity of the caller; authorization – determining if the authenticated caller has permission to perform the requested operation; encryption – ensuring that the data transmitted over the network can’t be read by unauthorized parties. Systems such as gRPC that sit on top of HTTP and HTTP/2 use Transport Layer Security (TLS) to support encrypted, authenticated RPC communication.