MapReduce
A framework for large-scale parallel processing
Paul Krzyzanowski
November 2023
Goal: Create a distributed computing framework to process data on a massive scale.
Introduction
Processing huge data sets (e.g., the contents of trillions of web pages or social networks) requires iterating through a lot of data. Even if there’s not a lot of computation per object, the time required to iterate through billions or trillions of them becomes substantial. For this reason, it becomes attract to divide the work among many computers, each working on just a part of the data set.
The other problem we run into is that we can’t just put all that data on a giant file server and have thousands of computers access it concurrently since that will create a bandwidth bottleneck in getting the data to all the computing elements. To solve this problem, we need to distribute both the computing and the storage.
Parallel programming
Most of the programming we do tends to be serial in design and execution. We tackle many problems in a sequential, stepwise manner and this is reflected in the corresponding program. With parallel programming, we break up the processing workload into multiple parts, each of which can be executed concurrently on multiple processors. Not all problems can be parallelized. The challenge is to identify as many tasks as possible that can run concurrently. Alternatively, we can take a data-centric view of the problem. In this case, we have a lot of data that needs to be processed and it might be possible to identify groups of data that can be processed concurrently. If the results of working on one chunk of data do not affect the processing of another chunk then the chunks can be processed by two processors at the same time. Data can be split among multiple concurrent tasks running on multiple computers.
The most straightforward situation that lends itself to parallel programming is one where there is no dependency among data. Data can be split into chunks and each process is then assigned a chunk to work on. Those processors will not have to exchange data with each other. If we have lots of processors, we can get the work done faster by splitting the data into lots of chunks and set up a coordinator to assign tasks to each computer. A master/worker design is one where a master process coordinates overall activity. It identifies the data, splits it up based on the number of available workers, and assigns a data segment to each worker. A worker receives the data segment from the master, performs whatever processing is needed on the data, and then sends results to the master. In the end, the master can track the status of the workers and send the results back to the user or application that made the initial request.
MapReduce
MapReduce is a large-scale data processing framework created by Google to build an inverted index1 to support their web search service. This framework turned out to be a framework that was useful for many other applications involving the processing and generating large data sets efficiently and reliably.
The key challenges that MapReduce aimed to address were:
1. Scalability
Traditional data processing systems were not scaling effectively with the rapidly increasing data sizes. MapReduce was designed to process large data sets across distributed computing resources efficiently.
2. Fault Tolerance
The likelihood of node failure in large-scale distributed computing is significant. MapReduce was built with mechanisms to handle failures gracefully, allowing data processing to continue despite node failures.
3. Simplicity of Data Processing
The framework simplified the programming model for large data sets. It abstracted the complexities of distributed computing, data partitioning, and fault tolerance, enabling developers to concentrate on the processing logic.
4. Data Locality
Transferring large data sets across a network is inefficient. MapReduce was optimized to process data on the nodes where it is stored, reducing network traffic and improving overall performance. This was a key part of the Google cluster environment: compute nodes and data storage nodes are not separate entities.
5. Flexibility
The framework was not overarching, which made it easy to understand and generic enough to be applicable to a broad range of applications, from web page indexing to machine learning tasks.
MapReduce Etymology
MapReduce is was created at Google in 2004 by Jeffrey Dean and Sanjay Ghemawat. The name is inspired from map and reduce functions in the LISP programming language. In LISP, the map function takes as parameters a function and a set of values. That function is then applied to each of the values. For example:
(map ‘length ‘(() (a) (ab) (abc)))
applies the length function to each of the three items in the list. Since length returns the length of an item, the result of map is a list containing the length of each item:
(0 1 2 3)
The reduce function is given a binary function and a set of values as parameters. It combines all the values together using the binary function.
If we use the + (add) function to reduce the list (0 1 2 3):
(reduce #'+ '(0 1 2 3))
we get:
6
If we think about how the map operation works, we realize that each application of the function to a value can be performed in parallel (concurrently) since there is no dependence of one upon another. The reduce operation can take place only after the map is complete since it uses the results of map.
MapReduce is not an implementation of these LISP functions; they merely served as an inspiration and an etymological predecessor.
The MapReduce framework
MapReduce is a framework for parallel computing. Programmers get a simple API2 and do not have to deal with issues of parallelization, remote execution, data distribution, load balancing, or fault tolerance. The framework makes it easy for one to use thousands of processors to process huge amounts of data (e.g., terabytes and petabytes)3. It hides all the complexity. The programmer can run the same code regardless of whether there is one computer or there are tens of thousands that will work on the problem.
From a user’s perspective, there are two basic operations in MapReduce: Map and Reduce.
The Map function reads a stream of data and parses it into intermediate <key, value> pairs. When that is complete, the Reduce function is called once for each unique key that was generated by Map and is given the key and a list of all values that were generated for that key as a parameter. The keys are presented in sorted order.
As an example of using MapReduce, consider the task of counting the number of occurrences of each word in a large collection of documents. The user-written map function reads the document data and parses out the words. For each word, it writes the <key, value> pair of <word, 1>. That is, the word is treated as the key and the associated value of 1 means that we saw the word once. This intermediate data is then sorted by the key values in the MapReduce framework and the user’s reduce function is called for each unique key. Since the only values are the count of 1, reduce is called with a list of a “1” for each occurrence of the word that was parsed from the document. The function simply adds up all these ones to generate a total count for that word. Here’s what the logic looks like in pseudocode:
map(String key, String value):
// key: document name, value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word; values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Let us now look at what happens in greater detail.
MapReduce: More Detail
To the programmer, MapReduce appears as an API: communication with the various machines that play a part in execution is hidden, as is all the coordination that is required to run the tasks. MapReduce is implemented in a master/worker configuration, with one master coordinating many workers. A worker may be assigned a role of either a map worker or a reduce worker.
Step 1. Split input

Figure 1. Split input into shards
The first step, and the key to massive parallelization in the next step, is to split the input into multiple pieces. Each piece is called a split, or shard. For M map workers, we want to have M shards, so that each worker will have something to work on. The number of workers is mostly a function of the amount of machines we have at our disposal. It might also limited by the amount of sharing (e.g., if a shard is a single file, then M might be the number of files) or by budgetary constraints (if there is a cost for renting the systems, as with cloud services such as Amazon’s Elastic MapReduce).
The MapReduce library of the user program performs this split. The actual form of the split may be specific to the location and form of the data. MapReduce allows the use of custom readers to split a collection of inputs into shards based on specific format of the files.
Step 2. Fork processes
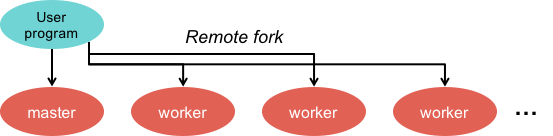
Figure 2. Remotely execute worker processes
The next step is to create the master and the workers. The master is responsible for dispatching jobs to workers, keeping track of progress, and returning results. The master picks idle workers and assigns them either a map task or a reduce task. A map task works on a single shard of the original data. A reduce task works on intermediate data generated by the map tasks. In all, there will be M map tasks and R reduce tasks. The number of reduce tasks is the number of partitions defined by the user. A worker is sent a message by the master identifying the program (map or reduce) it has to load and the data it has to read.
Step 3. Map
Figure 3. Map task
Each map task reads from the input split that is assigned to it. It parses the data and generates <key, value> pairs for data of interest. In parsing the input, the map function is likely to get rid of a lot of data that is of no interest. By having many map workers do this in parallel, we can linearly scale the performance of the task of extracting data.
MapReduce supports reading data in different formats, each of which can split data into meaningful ranges for processing as map tasks. This ensures that records don’t get split; for example, a line isn’t broken if we’re reading line-oriented data. Programmers can add their own code by implementing a reader interface. Readers need not read data only from a file; it can come from multiple files or as the output of a database query.
Step 4: Map worker: Partition
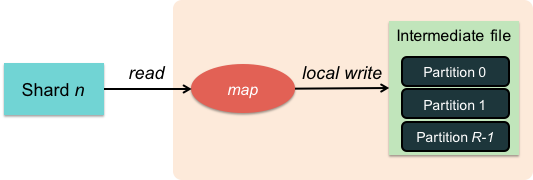
Figure 4. Create intermediate files
The stream of <key, value> pairs that each worker generates is buffered in memory and periodically stored on the local disk of the map worker. This data is partitioned into R regions by a partitioning function.
The partitioning function is responsible for deciding which of the R reduce workers will work on a specific key. The default partitioning function is simply a hash of key modulo R but a user can replace this with a custom partition function if there is a need to have certain keys processed by a specific reduce worker.
Step 5: Reduce: Shuffle and Sort
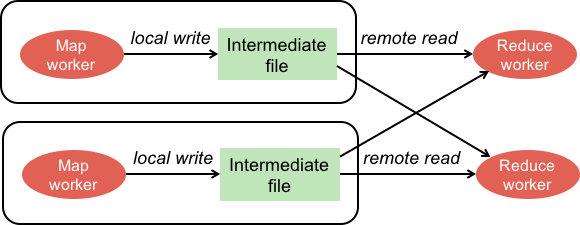
Figure 5. Sort and merge partitioned data
When each map worker has completed its work, it notifies the master, telling it the locations of the partition data on its local disk.
When all the map workers have completed their work, the master notifies the reduce workers to start working. The first thing a reduce worker needs to is to get the data that it needs to present to the user’s reduce function. The reduce worker contacts every map worker via remote procedure calls to transfer the <key, value> data that was targeted for its partition. This step is called shuffling.
The received data is then sorted by the key values. Sorting is needed since it will usually be the case that there are many occurrences of the same key coming from multiple map workers. After sorting, all occurrences of the same key are grouped together. That makes it easy for the reduce worker to see all the data that is associated with a single key.
Step 6: Reduce function

Figure 6. Reduce function writes output
With data sorted by keys, the user’s reduce function can now be called. The reduce worker calls the reduce function once for each unique key. The function is passed two parameters: the key and the list of intermediate values that are associated with the key.
Each reduce function appends its results to a file created by its reduce worker process.
Step 7: Done!
When all the reduce workers have completed execution, the master passes control back to the user program. Output from MapReduce is stored in the R output files that the R reduce workers created.
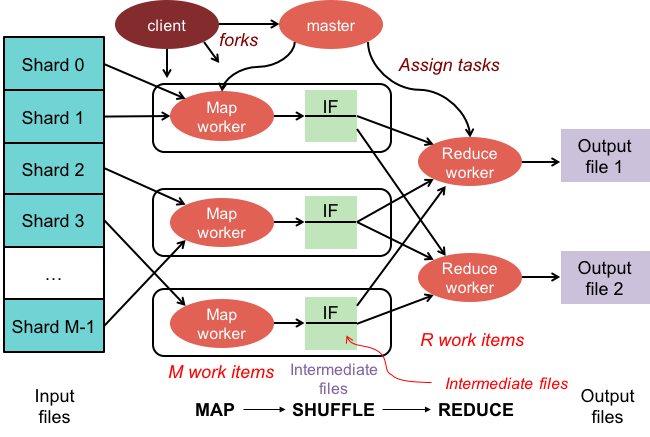
The big picture
Figure 7 illustrates the entire MapReduce process. The client library initializes the shards and creates map workers, reduce workers, and a master. Map workers are assigned a shard to process. If there are more shards than map workers, a map worker will be assigned another shard when it is done. Map workers invoke the user’s Map function to parse the data and write intermediate <key, value> results onto their local disks. This intermediate data is partitioned into R partitions according to a partioning function. Each of R reduce workers contacts all of the map workers and gets the set of <key, value> intermediate data that was targeted to its partition. It then calls the user’s Reduce function once for each unique key and gives it a list of all values that were generated for that key. The Reduce function writes its final output to a file that the user’s program can access once MapReduce has completed.
Dealing with failure
The master pings each worker periodically. If no response is received within a certain time, the worker is marked as failed. Any map or reduce tasks that have been assigned to this worker are reset back to the initial state and rescheduled on other workers.
Counters
A common need in many MapReduce tasks is to refer to counts of various events. For example, we might need to know the total number of words or documents processed if we need to compute percentages. The MapReduce framework provides a counter mechanism that allows user code to create counters and increment them in either map or reduce functions. The individual counters from these workers are periodically sent to the master, which aggregates the values and provides them to user code once the entire MapReduce job is completed.
Locality
MapReduce is built on top of GFS, the Google File System. Input and output files are stored on GFS. The MapReduce workers run on GFS chunkservers. The MapReduce master attempts to schedule a map worker onto one of the machines that holds a copy of the input chunk that it needs for processing. MapReduce may also read from or write to Bigtable (a table-based storage system which lives on GFS) or from arbitrary data sources with custom Readers.
What is it good for and who uses it?
MapReduce is clearly not a general-purpose framework for all forms of parallel programming. Rather, it is designed specifically for problems that can be broken up into the map-reduce paradigm. Perhaps surprisingly, there are a lot of data analysis tasks that fit nicely into this model. While MapReduce is heavily used within Google, it also found use in companies such as Yahoo, Facebook, and Amazon.
The original, and proprietary, implementation was done by Google. It is used internally for a large number of Google services. The Apache Hadoop project built a clone based largely on Google’s description of its architecture. Amazon, in turn, uses Hadoop MapReduce running on their EC2 (elastic cloud) computing-on-demand service to offer the Amazon Elastic MapReduce service. Microsoft MapReduce jobs on HDInsight and Google offers it as a customer-facing service as MapReduce for App Engine via Google Cloud.
Some problems it has been used for include:
- Distributed grep (search for words)
- Map: emit a line if it matches a given pattern
- Reduce: just copy the intermediate data to the output
- Count URL access frequency
- Map: process logs of web page access; output <URL, 1>
- Reduce: add all values for the same URL
- Reverse web-link graph
- Map: output <target, source> for each link to target in a page source
- Reduce: concatenate the list of all source URLs associated with a target. Output <target, list(source)>
- Inverted index
- Map: parse document, emit <word, document-ID> pairs
- Reduce: for each word, sort the corresponding document IDs; emits a <word, list(document-ID)> pair. The set of all output pairs is an inverted index
Other examples that demonstrate the versatility of MapReduce in handling various data analysis tasks include the following:
Log Analysis: MapReduce can be used for analyzing logs generated by web servers or other systems. Mappers can extract relevant information from each log entry, such as timestamps, IP addresses, or error codes. Reducers can aggregate the extracted data to identify patterns, anomalies, or generate statistical summaries.
Recommender Systems: MapReduce can help build recommender systems that provide personalized recommendations to users. Mappers can process user behavior data, such as viewing history or purchase records, while reducers can analyze the data to generate recommendations based on patterns and similarities between users or items.
Image Processing: MapReduce can also be utilized in image processing tasks. Mappers can process individual images, performing operations like image resizing, feature extraction, or object recognition. Reducers can combine the processed images or extract insights from the image data, such as generating histograms or analyzing image similarity.
Social Network Analysis: MapReduce can be used to analyze large-scale social network data. Mappers can traverse the network structure and extract useful information, such as identifying influencers or detecting communities. Reducers can then process the extracted data to uncover social network patterns or perform graph algorithms. As we will later see, even though MapReduce can and has been used for this purpose, it is not an ideal framework for graph analysis since many graph problems require many iterations, each of which will translate into a separate MapReduce job where the outputs of the previous job become the inputs to the next one.
References
Jeffrey Dean and Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, OSDI’04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December, 2004.
The introductory and definitive paper on MapReduce: Jerry Zhao, Jelena Pjesivac-Grbovic, MapReduce: The programming model and practice, SIGMETRICS’09 Tutorial, 2009.
Oscar Stiffelman, A Brief History of MapReduce, Medium.com article, April 26, 2018.
Tutorial of the MapReduce programming model: MapReduce.org
Amazon’s MapReduce service: Amazon Elastic MapReduce
MapReduce course: a part of 2008 Independent Activities Period at MIT
This is an update of a document originally created on November 2018.
-
An inverted index is a data structure that makes full-text searches efficient. It maps text to its location in a database (e.g., a location in a document or the list of documents where it appears). ↩︎
-
API = Application Programming Interface, a library that provides a set of functions that a program can call. The programmer who uses these functions can be ignorant of their underlying implementation. ↩︎
-
a terabyte is 1,000 gigabytes, or 1012 bytes. A petabyte is 1,000 terabytes, or 1015 bytes. We usually use base-2 measurements, so the prefix tera- refers to 240 and peta- to 250. In 2000, the International Electrotechnical Commission (IEC) proposed a naming scheme of gibibyte (GiB), tebibyte (TiB), and pebibyte (PiB) for the base-2 versions but these names are not always used. For our discussions, this distinction does not matter; we are simply referring to huge amounts of data. ↩︎