Google cluster architecture
Web search for a planet – overview
Paul Krzyzanowski
April 23, 2020
Goal: Create a system architecture that can scale to handle large-scale web searches.
Introduction
We will examine at the Google Cluster Architecture. This does not represent the current Google environment but rather one from the early days of Google. This discussion summarizes Web Search for a Planet: The Google Cluster Architecture. The paper dates back to 2003.
Since then, there has been a lot of scaling and re-engineering. However, even in the early 2000s, Google ran an environment that was scaled bigger than the needs of most organizations use today. Moreover, the architecture puts forth a few basic design principles that are very much applicable. It shows how huge scalability has been achieved using commodity computers by exploiting parallelism.
What happens when you do a search?
Google started, and is still primarily perceived, as a web search company. Google owns about 95% of that market. The company’s main source of revenue is web-based advertising and the biggest chunk of that revenue comes from search.
We will look at the architecture that was designed to run Google search. We will not look at the underlying PageRank algorithms or how search-relevant ads are retrieved here but rather how query processing was built to scale.
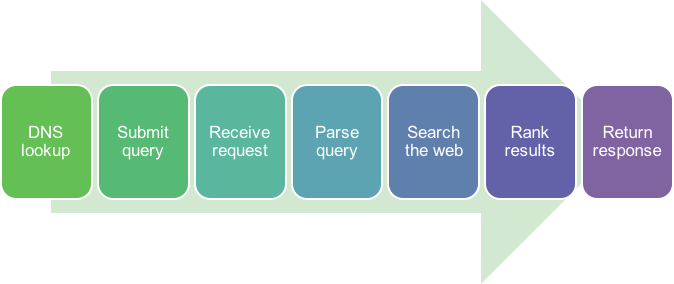
Let’s consider the key things that happen in the quarter second or so before you get your results from a google search:
- You go to
www.google.com. To do this, you computer must perform a DNS (Domain Name Service) lookup to find Google’s IP address, establish a secure connection using TLS (Transport Layer Security), and request an HTML page containing the search form. - You fill in your search terms and submit the search.
- A web server receives your HTML POST via HTTP.
- It parses the message and parses the query.
- The service does a search through its database of all crawled web pages – well over 100 million gigabytes just for the index. This is the hard part!
- Optionally, the results may be personalized if the system can identify you.
- The resulting data is ranked to present the most relevant results first.
- Finally, the web server sends those results as an HTML message back to the browser.
Some statistics
To get an idea of the scale of search, here are some recent statistics:
- 3.5 billion searches are performed each day; trillions of searches per year
- Search volume grows approximately 10% each year; the ability to scale the infrastructure is important.
- 16–20% of Google searches have never been searched before. Between this statistic and the vast diversity of searches that have been performed, this suggests that caching past results will not help much.
- The average user interaction session lasts under a minute.
- Hundreds of billions of web pages are indexed. The index is over 100 million gigabytes in size; that’s 1017.
- Most queries tend to be short. Single-word queries account for 21.7% of searches, two-word queries: 24%, three-word: 19.6%, four-word: 13.9%, five-word: 8.7%, and all queries that are longer than five words account for 12.1% of searches.

Requirements
To complete its task, a single Google query needs to search through hundreds of terabytes of data and consume tens of billions of CPU cycles.
Collectively, the system needs to support tens of thousands of queries per second. It also needs to be always available, so it needs a fault-tolerant design.
Buying, administering, and powering a collection of computers to provide this kind of performance costs money. Operating costs are important. We want the most economical solution that delivers the desired performance. The entire system needs to be energy efficient to keep operating costs down; price per watt and performance per watt matter.
Because there will be a high volume of concurrent queries, we need to parallelize the workload. Individual CPU performance is less important than the overall price-performance ratio.
Key design principles
The common wisdom for designing systems for large-scale production use was to buy expensive, high-performing, reliable servers, devices that are often referred to as “enterprise-grade” or “server class.” Google took a different path. Google engineers focused their efforts on designing software to deal with any reliability problems in hardware. They did a cost-benefit analysis.
The two key factors in choosing the systems for the Google cluster are:
- Energy efficiency
- Price-performance ratio
Reliability in software, not hardware
By placing the reliability in software and not the underlying hardware, Google engineers were able to use inexpensive off-the-shelf PCs running Linux and keep hardware costs low. Using an open source operating system ensured they didn’t have to license software. A few hundred thousand licenses of Microsoft Windows aren’t cheap.
The related insight was optimizing the design for overall throughput, not peak response time from any one server. Google had the benefit of realizing that search can be parallelized well. Because they can split up the workload, the price-performance ratio of the aggregate cluster becomes more important than peak processor performance. They’re going for high throughput.
Instead of getting the fastest systems, services can be replicated onto many unreliable PCs. Software can detect failures and balance the load among the working systems. This approach affected virtually all areas of system design.
Life of a Google query – step 1: DNS
Lets look at how a query gets processed.
Google maintains multiple data centers worldwide, each containing thousands of computers. Having replicated data centers provides a high level of fault tolerance. If an entire data center gets disconnected or destroyed, the service can still function.
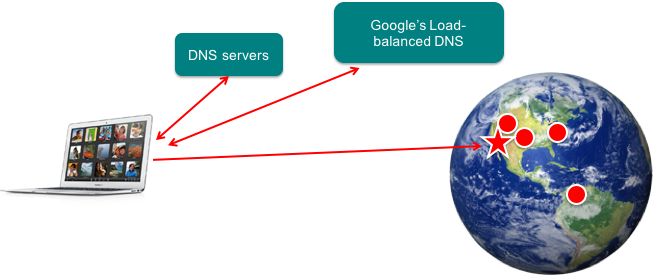
When someone issues a google query, they first need to look up the address for google.com. This is handled through DNS, the Internet’s Domain Name System. In performing a DNS query, a computer may contact several servers (e.g., ask the name server responsible for the .com top-level domain for the address of the server responsible for google.com).
This DNS query will eventually reach one of several DNS servers that Google operates. The DNS server looks at the source address of the query and returns the IP address of a server at a data center that is closest to that user. This is a form of DNS-based load balancing and reduces latency to the server.
Life of a Google – step 2: Web server
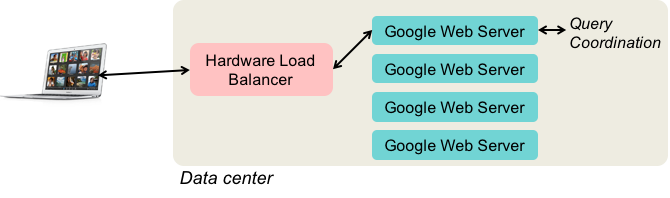
Now that the user’s computer knows the IP address of a Google web server, it can set up a TCP connection to that server and, via HTTP, send an HTML message containing the query.
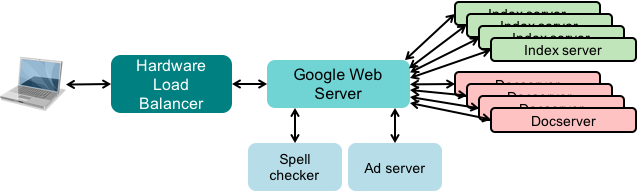
This request goes to the chosen Google data center and hits a hardware load balancer. Many routers provide this load balancing capability. One external IP address is mapped to one of a set of internal addresses. This balances the load from multiple queries across many Google Web Servers.
The Google Web Server is responsible for managing the lifecycle of the query and getting the response back to the user. It doesn’t handle the search itself; it delegates that to other systems and just aggregates the results, eventually composing an HTML response that is sent back to the user.
Life of a Google query – step 3: inverted index
The actual search takes place in two phases. The web server first sends the query to index servers.
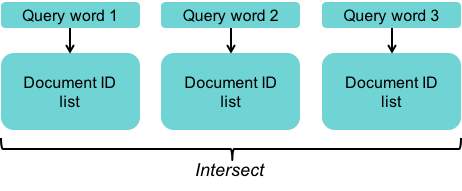
Each index server contains an inverted index. An inverted index is a data structure that maps some content, such as a word, to its location in the document, such as a URL. Think of it as a hash map.
In the case of Google’s index servers, each lookup of a word will return a hit list – the list of matching documents that contain that word.
By intersecting hit lists from individual words, the server can determine a relevance score for each document. Later, the results presented to the user will be sorted by this relevance score.
There’s a lot of data - parallel search
The problem with building an index server is that it needs to search through the index of every web page on the planet.
Google has processes that constantly crawl the web, downloading page content and appending it to files stored in the Google File System (GFS). Back in the 2000s, the text part of web pages consumed tens of terabytes of text data. Now they’re hundreds of terabytes. Hence, the inverted index that maps words to documents was also many terabytes in size. We need to search multiple words and each word needs to be searched within a huge index.
The good thing is that we can do multiple searches in parallel. First, we can search individual words in parallel and find the intersection later. Second, we can search a single index in parallel. The inverted index is broken into chunks. Chunks of a bigger collection of data are called shards and the process is known as sharding. Each index shard contains index data for a random subset of documents.
Each index shard is replicated among a pool of servers so that query requests for each shard are load-balanced among the machines in this pool.
To do an inverted index search, the query is sent – in parallel – to each pool of index servers. Each pool of index servers contains an index for just a subset of documents.
Each pool of index servers for a shard also contains a load balancer that directs the request to a single index server that processes the search.
The results of the individual queries are returned to the web server and merged to create an ordered list of document identifiers (docids).
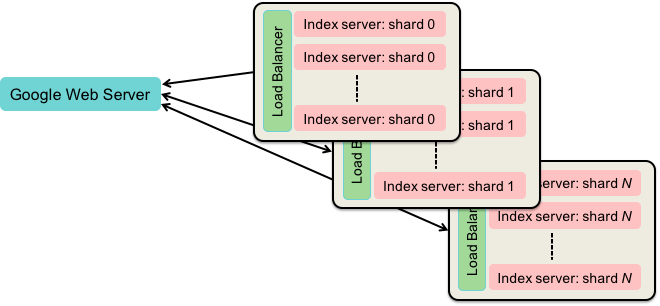
Sharded & Replicated Index Servers
This diagram shows how divide the index index into multiple shards, each of which isn’t very big and can be searched quickly.
Each index shard is replicated onto many servers to form a load balanced pool of servers.
Life of a Google query – Step 4: docid lookup
The first phase of the query was looking up each individual word across a set of index servers and generating a merged list of document IDs.
The second phase is turning those document IDs into something that will make sense to the user. For this, another set of servers is used. These are document servers and contain the actual web pages that the document IDs (docids) referenced.
A document server is given a document ID and returns back the:
- URL
- Page title
- A document summary that is related to the query
Parallelizing document lookup
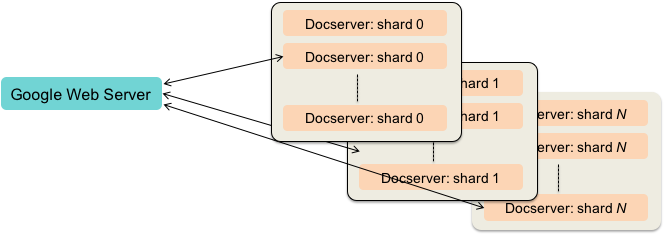
The same sharding approach that was used for index servers is used for document servers:
The collection of documents – all the web pages Google knows about – is randomly divided into multiple groups. Each document server is responsible for one of these shards, or groups of pages. As with index servers, every document server is replicated and load balanced.
A document ID query is sent in parallel to each pool of document servers, where a load balancer in front of each one directs a request to a specific server.
After this phase, the Google Web Server has a ranked list of document titles, URLs, and descriptions.
Additional operations
There are other services the web server calls upon as well, such as spell-checking and ad generation. Over time, semantic analysis and more natural-language processing capabilities were added as well as taking a user’s previous search history and preferences into account.
What makes this system work well?
A huge benefit of the web search problem is that queries parallelize exceptionally well. A large lookup is is split among multiple servers and the results are merged. Merging results, which are a lot shorter than the raw index, is inexpensive compared to searching through the data. This happens both in the inverted index search and the document search.
This approach also reduces latency since so much is done in parallel. Because of the parallelism, individual CPU speeds don’t matter as much.
There is a lot of load balancing going on:
- DNS load balances across data centers
- Hardware load balancers divide the load across web servers
- Load balancers for replicated index servers
- Load balancers for document servers as well as other services, such as ad servers and spelling checkers.
Load balancers are also crucial to the reliability of the system. Software monitors all the servers. If any server is not running correctly, it is taken out of the load balanced pool of servers until it is fixed.
Updating and scaling
Virtually all access to the index and document servers is read-only. Writes, which are database updates, to these servers are infrequent compared to the amount of read operations.
When updates happen, the individual system can be taken out of the load balancer for the duration of the update. This avoids problems of data integrity and having to lock data.
Shards don’t need to communicate with each other, so replication becomes simple.
Scaling is also straightforward. More shards can be added as the number of documents grows. If query traffic increases, more replicas can be added to each pool of servers to increase throughput.
Summary
Google summarizes the design principles used in constructing the Google cluster environment:
- Use software to achieve reliability
- Instead of spending money on expensive hardware, redundant power supplies, redundant disks, etc. All those components will ultimately fail in any case, so the system has to handle failure.
- Use replication for high throughput.
- This also provides high reliability.
- Price-performance is more important that peak CPU performance
- The system was designed with a concern for the cost needed to achieve a certain level of total performance.
- Use commodity hardware
- The use of commodity components reduces the cost of computation. This relates to software-based reliability and price-performance. It includes using commodity disks as well as PCs.
Hardware
As an addendum, let’s take a brief look at hardware concerns.
Hardware choices, of course, evolved over the years. Google (and other companies who take a similar approach, such as Facebook) evaluates the performance of various CPU architectures across multiple generations. The end goal is always the ultimate cost per query, which includes system cost, rack cost, power consumption, and operating costs.
Energy efficiency is a big concern. Because Google operates in such high volumes, it makes sense to design their own systems. Each server, for example, has its own battery rather than using a shared uninterruptible power supply. This is cheaper, more power-efficient, and ensures that the backup power capacity always matches the number of servers.
Also, all systems are powered with 12 volts DC rather than requiring an AC power supply. This choice allows power supplies on servers to run more efficiently.
In later years, Google placed a huge focus on infrastructure security to authenticate devices at a hardware level. Current systems and peripherals have custom security chips and cryptographic signatures for each layer of software, down to the system firmware and bootloader.