Bitonic Sort: MPI Implementation
Contents
MPI Bitonic Sort Code
main.cpp
Exported from Notepad++
#include "bitonic_sorter.h"
#include <stdio.h>
#include <stdlib.h>
#include <ctime>
#include <mpi.h>
#include <string.h>
void generateDataSet(int dataSet[],int size) {
printf( "[0] creating dataset ...\n");
srand ((unsigned int) time(NULL) );
for ( int index = 0; index < size; ++index) {
dataSet[index] = index;
}
}
void randomizeData(int dataSet[],int tempDataSet[],int size){
printf( "[0] dataset of size %d being randomized ...\n",size);
for ( int index = 0; index < size; ++index) {
tempDataSet[index] = rand();
}
SelectionSort(tempDataSet,dataSet, size);
}
void SelectionSort(int a[],int b[], int size)
{
int i;
for (i = 0; i < size - 1; ++i)
{
int j, min, tempA,tempB;
min = i;
for (j = i+1; j < size; ++j)
{
if (a[j] < a[min])
min = j;
}
tempB = b[i];
tempA = a[i];
a[i] = a[min];
b[i] = b[min];
a[min] = tempA;
b[min] = tempB;
}
}
void masterHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat){
for(int i=1;i<numprocs;i++)
{
sprintf(buff, "hey %d! ", i);
MPI_Send(buff, BUFSIZE, MPI_CHAR, i, TAG, MPI_COMM_WORLD);
}
for(int i=1;i<numprocs;i++)
{
MPI_Recv(buff, BUFSIZE, MPI_CHAR, i, TAG, MPI_COMM_WORLD, &stat);
printf("[%d]: %s\n", i, buff);
}
}
void slaveHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat,int myid){
// receive from rank 0
char idstr[32];
MPI_Recv(buff, BUFSIZE, MPI_CHAR, 0, TAG, MPI_COMM_WORLD, &stat);
sprintf(idstr, "Processor %d ", myid);
strncat(buff, idstr, BUFSIZE-1);
strncat(buff, "reporting for duty", BUFSIZE-1);
// send to rank 0
MPI_Send(buff, BUFSIZE, MPI_CHAR, 0, TAG, MPI_COMM_WORLD);
}
void distributeIntArray(int numprocs,int dataSet[],int SIZE){
for(int dest = 1; dest <= numprocs; dest++){
printf("sending data to processor %ld, size = %ld\n",dest,SIZE/(numprocs-1));
//MPI_Send(dataSet+(dest/2), SIZE / (numprocs-1), MPI_INT, 1, dest, MPI_COMM_WORLD);//11
MPI_Send(dataSet, SIZE, MPI_INT, dest, 1, MPI_COMM_WORLD);
}
printf("sending data to p");
MPI_Finalize();
}
void sendIntArray(int numprocs,int dataSet[],int SIZE,int target){
for(int dest = 1; dest <= numprocs; dest++){
printf("sending data to processor %ld, size = %ld\n",dest,SIZE/(numprocs-1));
//MPI_Send(dataSet+(dest/2), SIZE / (numprocs-1), MPI_INT, 1, dest, MPI_COMM_WORLD);//11
MPI_Send(dataSet, SIZE, MPI_INT, dest, 1, MPI_COMM_WORLD);
}
printf("sending data to p");
MPI_Finalize();
}
void recieveIntArray(int buf[],int len,MPI_Status *stat,int from){
printf("check \n");
MPI_Recv(buf, len, MPI_INT, from, 1,MPI_COMM_WORLD, stat);
printf("check1 %d\n",buf[63]);
}
void bitonicSort(int start, int len,int data[]) {
if (len>1) {
int split=len/2;
bitonicSort(start, split,data);
bitonicSort(start+split, split,data);
merge(start, len,data);
}
}
void merge(int start, int len,int data[]) {
if (len>1) {
int mid=len/2;
int x;
for (x=start; x<start+mid; x++)
compareAndSwap(data,x, x+mid);
merge(start, mid,data);
merge(start+mid, start ,data);
}
}
void compareAndSwap(int data[],int i, int j) {
int temp;
if (data[i]>data[j])
temp = data[i];
data[i] = data[j];
data[j] = temp;
}
bitonic_sorter.h
Exported from Notepad++
#include <mpi.h>
void generateDataSet(int dataSet[],int size);
void randomizeData(int dataSet[],int tempDataSet[],int size);
void SelectionSort(int a[],int b[], int size);
void masterHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat);
void slaveHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat,int myid);
void distributeIntArray(int numprocs,int dataSet[],int SIZE);
void recieveIntArray(int buf[],int len,MPI_Status *stat,int from);
void bitonicSort(int start, int len,int data[]);
void compareAndSwap(int data[],int i, int j);
bitonic_sorter.cpp
Exported from Notepad++
#include "bitonic_sorter.h"
#include <stdio.h>
#include <stdlib.h>
#include <ctime>
#include <mpi.h>
#include <string.h>
void generateDataSet(int dataSet[],int size) {
printf( "[0] creating dataset ...\n");
srand ((unsigned int) time(NULL) );
for ( int index = 0; index < size; ++index) {
dataSet[index] = index;
}
}
void randomizeData(int dataSet[],int tempDataSet[],int size){
printf( "[0] dataset of size %d being randomized ...\n",size);
for ( int index = 0; index < size; ++index) {
tempDataSet[index] = rand();
}
SelectionSort(tempDataSet,dataSet, size);
}
void SelectionSort(int a[],int b[], int size)
{
int i;
for (i = 0; i < size - 1; ++i)
{
int j, min, tempA,tempB;
min = i;
for (j = i+1; j < size; ++j)
{
if (a[j] < a[min])
min = j;
}
tempB = b[i];
tempA = a[i];
a[i] = a[min];
b[i] = b[min];
a[min] = tempA;
b[min] = tempB;
}
}
void masterHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat){
for(int i=1;i<numprocs;i++)
{
sprintf(buff, "hey %d! ", i);
MPI_Send(buff, BUFSIZE, MPI_CHAR, i, TAG, MPI_COMM_WORLD);
}
for(int i=1;i<numprocs;i++)
{
MPI_Recv(buff, BUFSIZE, MPI_CHAR, i, TAG, MPI_COMM_WORLD, &stat);
printf("[%d]: %s\n", i, buff);
}
}
void slaveHandshake(char buff[],int numprocs,int BUFSIZE,int TAG,MPI_Status &stat,int myid){
// receive from rank 0
char idstr[32];
MPI_Recv(buff, BUFSIZE, MPI_CHAR, 0, TAG, MPI_COMM_WORLD, &stat);
sprintf(idstr, "Processor %d ", myid);
strncat(buff, idstr, BUFSIZE-1);
strncat(buff, "reporting for duty", BUFSIZE-1);
// send to rank 0
MPI_Send(buff, BUFSIZE, MPI_CHAR, 0, TAG, MPI_COMM_WORLD);
}
void distributeIntArray(int numprocs,int dataSet[],int SIZE){
for(int dest = 1; dest <= numprocs; dest++){
printf("sending data to processor %ld, size = %ld\n",dest,SIZE/(numprocs-1));
MPI_Send(dataSet, SIZE, MPI_INT, dest, 1, MPI_COMM_WORLD);
}
printf("sending data to p");
MPI_Finalize();
}
void sendIntArray(int numprocs,int dataSet[],int SIZE,int target){
for(int dest = 1; dest <= numprocs; dest++){
printf("sending data to processor %ld, size = %ld\n",dest,SIZE/(numprocs-1));
MPI_Send(dataSet, SIZE, MPI_INT, dest, 1, MPI_COMM_WORLD);
}
printf("sending data to p");
MPI_Finalize();
}
void recieveIntArray(int buf[],int len,MPI_Status *stat,int from){
printf("check \n");
MPI_Recv(buf, len, MPI_INT, from, 1,MPI_COMM_WORLD, stat);
printf("check1 %d\n",buf[63]);
}
void bitonicSort(int start, int len,int data[]) {
if (len>1) {
int split=len/2;
bitonicSort(start, split,data);
bitonicSort(start+split, split,data);
merge(start, len,data);
}
}
void merge(int start, int len,int data[]) {
if (len>1) {
int mid=len/2;
int x;
for (x=start; x<start+mid; x++)
compareAndSwap(data,x, x+mid);
merge(start, mid,data);
merge(start+mid, start ,data);
}
}
void compareAndSwap(int data[],int i, int j) {
int temp;
if (data[i]>data[j])
temp = data[i];
data[i] = data[j];
data[j] = temp;
}
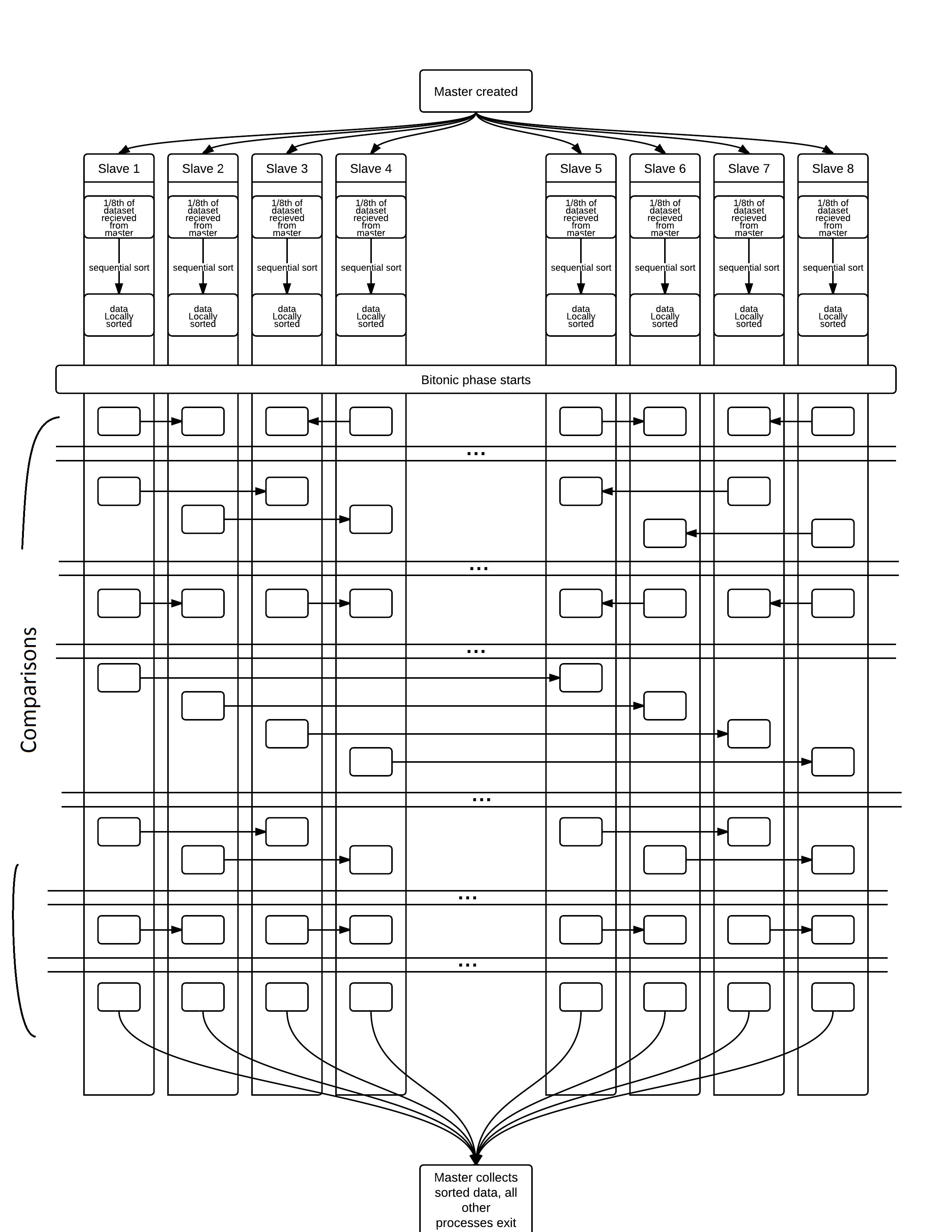
Example Using 8 Slave Processes
Click to view full size image.
Code Explanation
Firstly we need to look at what the code must accomplish. Since this is
most of a demonstration of MPI than trying to get the absolute fastest sort
we will only be using MPI for parrallelization. And although MPI supports it we
will not use shared memory since openMP does that better. It is optimized to run
on a cluster or supercomputer.
The solution: First we start by dividing the dataset into n parts, where n is the number
of slave processes available. Then those parts are sent to their respective process.
Then in unison each slave processor the portion of data it recieved from the master.
Now that we have n blocks of sorted data we must merge them to create a single contiguous
result. The data will be sorted globally in log2n steps. These steps will follow the
standard bitonic sort pattern. The first (n2-n)/2 steps are to create a bitonic sequence, and the
rest are to sort it. If you follow the above picture or the below pseudocode you can see each process makes a number of swaps with
different "partners".
Parallel Bitonic Sort Algorithm for processor Pk (for k := 0 : : : P 1)
d:= log P /* cube dimension */
sort(local datak) /* sequential sort */
/* Bitonic Sort follows */
for i:=1 to d do
window-id = Most Signi�cant (d-i) bits of Pk
for j:=(i-1) down to 0 do
if((window-id is even AND jth bit of Pk = 0) OR (window-id is odd AND jth bit of Pk = 1))
then call CompareLow(j)
else call CompareHigh(j)
endif
endfor
endfor
In the above image each arrow represents a comparehigh or comparelow call.
In these methods the data from the partners is sent to each other and then each one calls a merge
funtion, but only merges half of the data. The way in which the low and high function versions differentiate
is in the merge order. Low starts merging from the low end and high starts from the high end. They both finish when
they have merged half of the combined number of elements in each list.
The pseudocode for this is a follows:
High:
transfer the data to the paired process
receive the paired process’ data
start merging the from the high end data until you have merged n elements, where n was the original datasets length
low
same except you start to merge from the low end
once that all completes the data from all processes is sent back to the master and is in order.
Due to the way the data is sorted this is an unstable sorting algorithm
This method is designed to be run on a cluster computer system. If it were to be run on a standard computer it would suffer because there would be several redundent operations. Mainly you would have duplicated data at every bitonic step. Additionally unless you spawn the same number of processes as you have available threads waiting on processes to complete will create a bottleneck.
Sources
- http://web.mst.edu/~ercal/387/P3/pr-proj-3.pdf