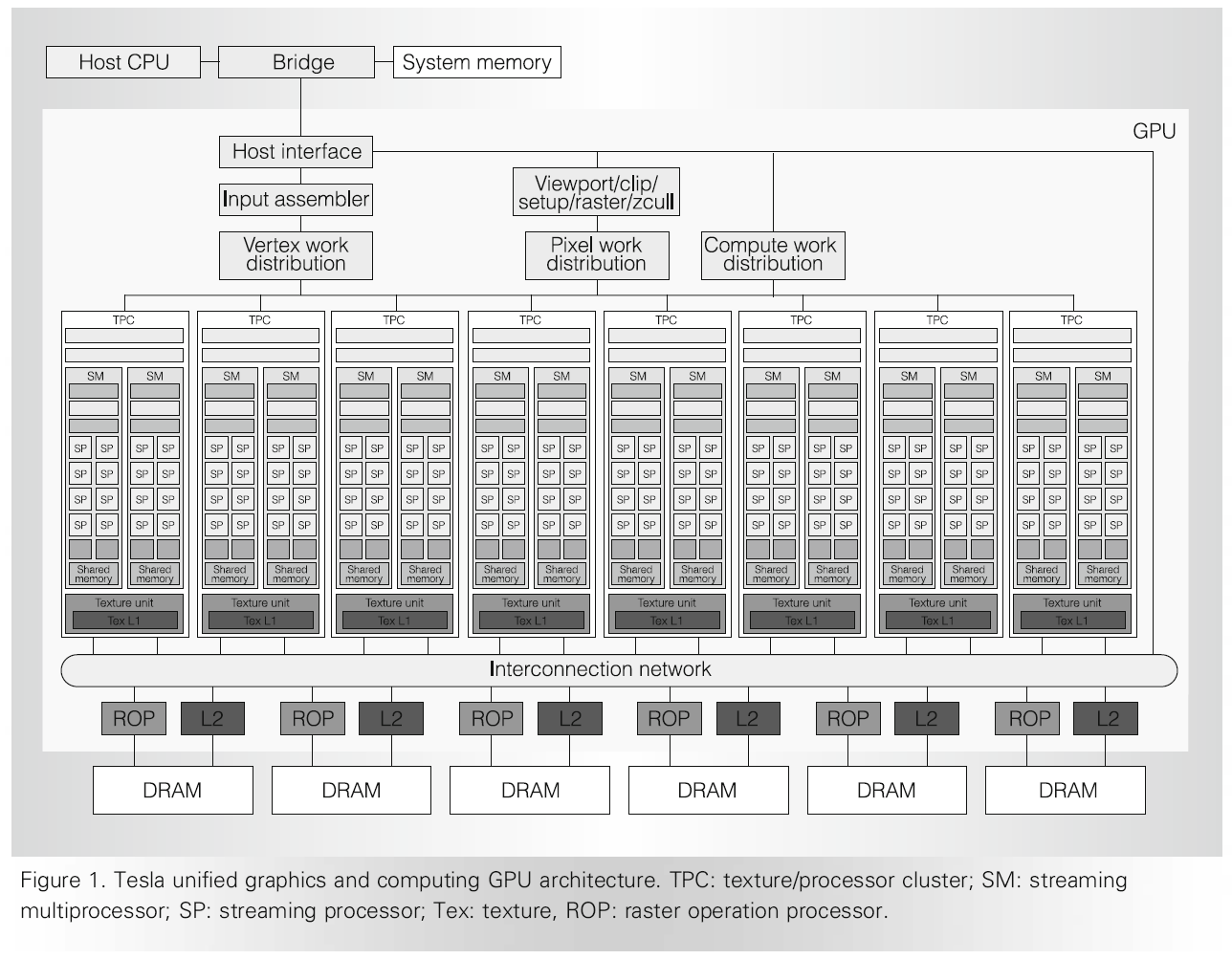
The layout of the Tesla GPU. Taken from pcinlife.com.
The Compute Unified Device Architecture, or CUDA, is a parallel computing architecture created by Nvidia. Unlike OpenMP and MPI, CUDA implements parallelism by exporting the parallel portions of a program for execution to a graphics processing unit, where hundreds of threads and processors divide and conquer the problem. This technique is known as general-purpose computing for graphics processing units (GPGPU). AMD has a similar GPU interface in Close-to-Metal/FireStream.
As computing technology increased in power and cost-efficiency, the demand for high-quality computer graphics skyrocketed, especially in the field of computer games. Thus, the graphics processing unit, or GPU, was born. It was originally meant to do intense graphics work in parallel, like rendering pixels on a screen.
Programmers soon tried to use the parallel computing power of the GPU. Algorithms could be ported to these parallel architectures by means of platforms like DirectX, OpenGL, and Cg. Unfortunately, this was a difficult process, as programmers needed to learn and use graphics APIs and the specific architectures of specific GPUs to even begin to use them. In addition, most graphics processing units at this time had no support for double-precision floating point numbers nor random read-and-writes to memory. This severely limited the flexibility of the programmer and possible applications, especially scientific ones that require precise floating-point mathematics.
CUDA was created from programmers at Nvidia in an attempt to create a universal GPU architecture for general-purpose parallel programming. It takes advantage of the graphics processing unit (GPU) in a computer to allow anyone with a CUDA-compliant GPU to run parallel programs. The architectuer allows developers to write programs compiled with a specialized CUDA compiler to be executed in parallel on the GPU. Supported languages include C and Fortran, with compilers provided by Nvidia; third-party support is also available for other languages including Java, C++, and Python.
Writing programs for Nvidia GPUs is possible with CUDA extensions to the C language. Programs are executed on a host CPU in serial until execution is transferred to the device, a CUDA-compliant GPU, where a parallel portion of the problem will be run. CUDA C functions allow programmers to transfer memory between both the host and device, as well as specify how methods should be run: on the CPU, on the device, or in parallel on each thread.
| Qualifier | Description |
| __device__ | On a function: indicates that it is executed and callable only on
the device. On a variable: resides only on the device. |
| __global__ | Indicates that a function is a kernel (called asynchronously); it is executed on the device, but callable only from the host. Must have a void return type. |
| __host__ | Function: Executed and callable only from the host, like a regular C function without any CUDA qualifiers. |
| __noninline__ __forceinline__ |
Compiler directives to inline or not inline a function. |
| __constant__ | Indicates that a variable resides in constant memory space. |
| __shared__ | Indicates that a variable resides in the shared memory space of a thread block. These variables can only be accessed from within the block and expires when the block terminates. |
| __restrict | Applied to function parameters; all variables with this qualifier cannot be aliased (none of them can point to the same object). |
To see examples of programs written in CUDA, see the links below:
Nvidia's graphics processing units are
There are currently three versions of CUDA GPU compute capabilities. New features have been added over time, and the Tesla architectures (Versions 1.x) are now obsolete.
The first architecture was known as Tesla, released for the Windows XP and Unix-based Red Hat operating systems. This generation of GPUs had up to 128 processing cores, support for single-precision floating point operations, and a maximum bandwidth of 76.8 GB/s per GPU. The Tesla was scalable, so that thousands of GPUs could be linked together for use in a supercomputer. It also had native support for C, BLAS, and libraries for the Fast Fourier Transform (FFT).
The next generation of GPUs, code-named Fermi, added new features to CUDA. Upgrades and changes included improved performance with double-precision numbers, more shared memory per block, and faster atomic functions. Fermi GPUs also received improved streaming multiprocessors, each with 32 CUDA cores. Memory performance and the parallel thread executor were also updated for more efficient performance.
The latest CUDA GPUs have updates that markedly change the way programs can be written for the architecture. Kepler symmetric multiprocessors (SMX) now have 192 cores, with a purported threefold increase in performance per watt. A new feature, Hyper-Q, aims to reduce idle CPU time by allowing several CPU cores to access the same GPU for added efficiency. The greatest change, however, comes in the addition of dynamic parallelism - the ability of threads to spawn their own parallel tasks. New kernels can be launched from within a thread itself, rather than from just the CPU. This allows for additional support for nested parallel loops and recursive parallel algorithms.