Bitonic Sort: OpenMP Implementation
Contents
OpenMP Bitonic Sort Code
main.c
Exported from Notepad++
#include<stdio.h>
#include<stdlib.h>
#define MAX(A, B) (((A) > (B)) ? (A) : (B))
#define MIN(A, B) (((A) > (B)) ? (B) : (A))
#define UP 0
#define DOWN 1
double walltime(double*); /* the clock on the wall */
void bitonic_sort_seq(int start, int length, int *seq, int flag);
void bitonic_sort_par(int start, int length, int *seq, int flag);
void swap(int *a, int *b);
int m;
main()
{
int i, j;
int n;
int flag;
int *seq;
double startTime, elapsedTime; /* for checking/testing timing */
double clockZero = 0.0;
int numThreads,id;
printf("Input the length of a sequence(a power of 2): ");
scanf("%d", &n);
seq = (int *) malloc (n * sizeof(int));
printf("Input the sequence: ");
for (i = 0; i < n; i++)
{
scanf("%d", &seq[i]);
}
// start
startTime = walltime( &clockZero );
numThreads = omp_get_max_threads();
// making sure input is okay
if ( n < numThreads * 2 )
{
printf("The size of the sequence is less than 2 * the number of processes.\n");
exit(0);
}
// the size of sub part
m = n / numThreads;
// make the sequence bitonic - part 1
for (i = 2; i <= m; i = 2 * i)
{
#pragma omp parallel for shared(i, seq) private(j, flag)
for (j = 0; j < n; j += i)
{
if ((j / i) % 2 == 0)
flag = UP;
else
flag = DOWN;
bitonic_sort_seq(j, i, seq, flag);
}
}
// make the sequence bitonic - part 2
for (i = 2; i <= numThreads; i = 2 * i)
{
for (j = 0; j < numThreads; j += i)
{
if ((j / i) % 2 == 0)
flag = UP;
else
flag = DOWN;
bitonic_sort_par(j*m, i*m, seq, flag);
}
#pragma omp parallel for shared(j)
for (j = 0; j < numThreads; j++)
{
if (j < i)
flag = UP;
else
flag = DOWN;
bitonic_sort_seq(j*m, m, seq, flag);
}
}
// bitonic sort
//bitonic_sort_par(0, n, seq, UP);
//bitonic_sort_seq(0, n, seq, UP);
//end
elapsedTime = walltime( &startTime );
/*
// print a sequence
for (i = 0; i < n; i++){
printf("%d ", seq[i]);
}
printf("\n");
*/
printf("Elapsed time = %.2f sec.\n", elapsedTime);
free(seq);
}
bitonic_sort_seq.c
Exported from Notepad++
void bitonic_sort_seq(int start, int length, int *seq, int flag)
{
int i;
int split_length;
if (length == 1)
return;
if (length % 2 !=0 )
{
printf("error\n");
exit(0);
}
split_length = length / 2;
// bitonic split
for (i = start; i < start + split_length; i++)
{
if (flag == UP)
{
if (seq[i] > seq[i + split_length])
swap(&seq[i], &seq[i + split_length]);
}
else
{
if (seq[i] < seq[i + split_length])
swap(&seq[i], &seq[i + split_length]);
}
}
bitonic_sort_seq(start, split_length, seq, flag);
bitonic_sort_seq(start + split_length, split_length, seq, flag);
}
bitonic_sort_par.c
Exported from Notepad++
void bitonic_sort_par(int start, int length, int *seq, int flag)
{
int i;
int split_length;
if (length == 1)
return;
if (length % 2 !=0 )
{
printf("The length of a (sub)sequence is not divided by 2.\n");
exit(0);
}
split_length = length / 2;
// bitonic split
#pragma omp parallel for shared(seq, flag, start, split_length) private(i)
for (i = start; i < start + split_length; i++)
{
if (flag == UP)
{
if (seq[i] > seq[i + split_length])
swap(&seq[i], &seq[i + split_length]);
}
else
{
if (seq[i] < seq[i + split_length])
swap(&seq[i], &seq[i + split_length]);
}
}
if (split_length > m)
{
// m is the size of sub part-> n/numThreads
bitonic_sort_par(start, split_length, seq, flag);
bitonic_sort_par(start + split_length, split_length, seq, flag);
}
return;
}
bitonic_swap.c
Exported from Notepad++
void swap(int *a, int *b)
{
int t;
t = *a;
*a = *b;
*b = t;
}
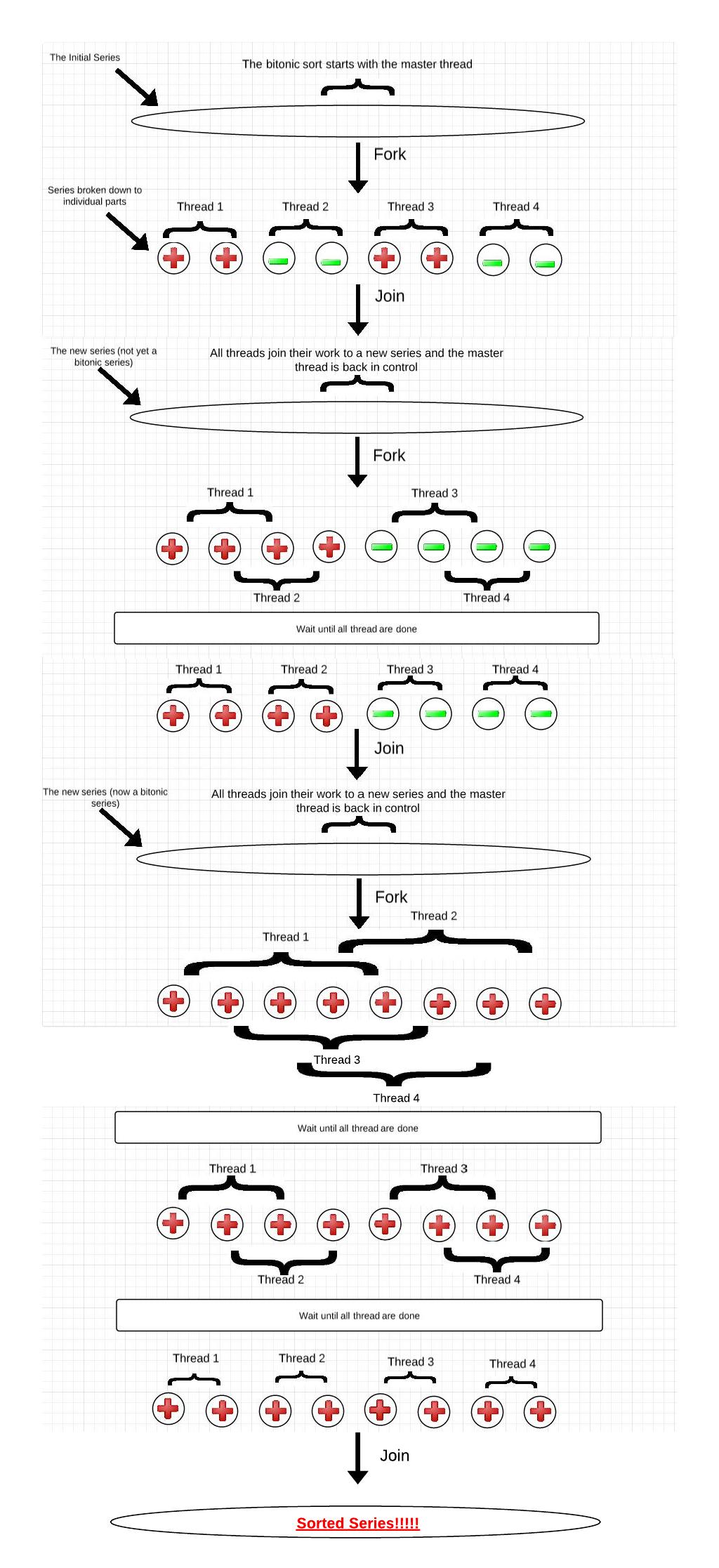
OpenMP Bitonic Sort Graphic
Simple example: A series of 8 numbers on a machine with 4 processors:
Click to view full size image.
Time Analysis/Speedups
I have tested the speedup achieved when using 2 and 4 cores,
and for input sizes that range from 100 to 5000 integer elements.
The speedup is not exactly double when the cores are 2 owing to the fact that with increase in number of cores we have additional overheads of data transfers and barrier.
The task spawning overhead is dominant at the lower array sizes, but it factors out with increasing array size and drops below 1% of total execution time! With total cores increased to 4, and 5000 integer elements, the theoretical upper bound for speedup is about 3.6 (with increasing array size, the processor has more computational time and the overheads factor out).
OpenMP Bitonic Sort Code Overview
Bitonic sort is one of the fastest sorting networks.
A sorting network is a special kind of sorting algorithm, where the sequence of comparisons is not data-dependent. The openMP implementation consists of 2 main operations for the algorithm: one is called a bitonic split and other being bitonic merge.
*In the bitonic split operation we will keep splitting the input data array into two bitonic sequences until a sequence with only one element is obtained.
*In the bitonic merge operation we will merge and again sort the different parts of the input array in a bitonic fashion.
The whole arrangement of splitting the input data into halves and the butterfly pattern provides a good combination of computation and communication between the threads which are responsible for sorting the input data.
In order to parallelize bitonic sort using OpenMP we must ask ourselves: Will all processes participate in sorting? How can we perform bitonic split between processes? Should a sequential sort be used for a certain input number? etc...
An OpenMP algorithm is mostly constructed of fork and joins, and in order to be as efficient as possible it is important to know when it is and isn’t relevant to make those forks and joins (what parts we should or shouldn’t parallelize). For the code presented above we are dividing the series into sub parts (based on the number of threads available). The number of items in each subpart is determined by the number of items in the sequence divided by max number of threads. We also have two methods: “bitonic_sort_seq” which sorts its input sequentially, and “bitonic_sort_par” which sorts its input in parallel.