Ba-du-ki is a Go (Ba-duk) playing program.
Ba-duk is a strategy board game invented by Chinese some 4000 years ago. It is normally played in the grid of 19x19 board but 13x13 or 9x9 board are also played mainly by beginners to learn the concept of the game. The players take alternative turns to place "stones", black and white, on the board. The objective of the game is to surround more empty grids than the opposite player. The 19x19 game normally takes around 250 to 300 moves unless one side resign.
Ba-duk could be an excellent AI research tool. Because of its size, 361 possible moves at the beginning of the game, the possibility of loops in Ko situation, and the freedom of move selection compared to the more well researched game such as Chess, Ba-duk offers the complexity that AI cannot solve right now. For a comparison, while the best Chess playing program beat the perhaps best human Chess player couple of years ago, the best Ba-duk playing program plays in the level of amateur intermediate.
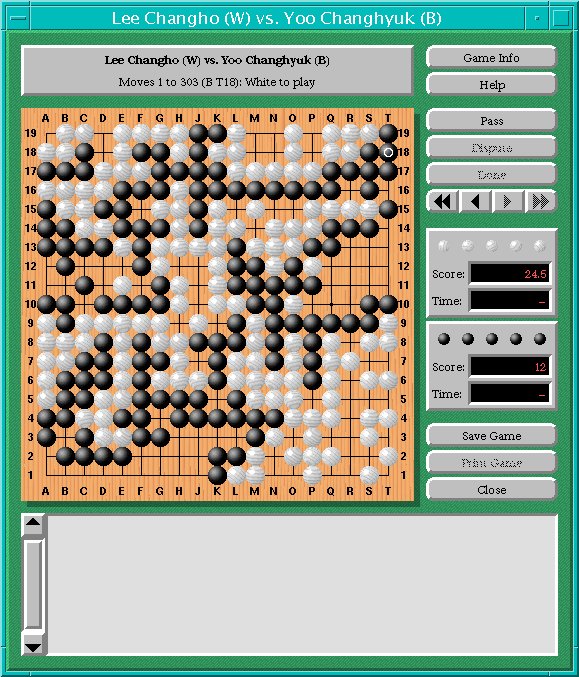
Here is the finished sample professional game.
Ba-du-ki plays Go in the 9x9 board which is smaller than regulation
19x19 board, but more manageable.
Here is the sample game that was played by Ba-du-ki vs Ba-du-ki.
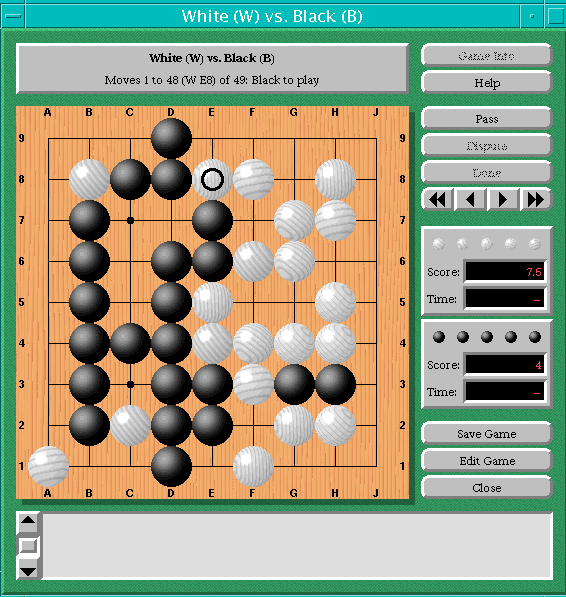
Ba-du-ki selects next move to play by choosing a random move that fits a simple constraint of keeping temp bigger than 0.75 out of 15 possible candidate moves that was preselected. Each position on board was assigned to an arbitrary value that I thought was reasonable estimation of relative position on board. For example the center position was given the value of 1 and the edge positions were given the value of 0.1. The program will keep track of 15 candidate moves, and when the move is played, it will be replaced in the 15 possible candidate pool by the next best move according to the position value.
I first started out to map the end game thinking that since there will be more or less smaller set of problems than the beginning or middle part of the game, but found out that even in those smaller set of problems, there were too many things to consider in order to play anything remotely close to the best play. By switching to the smaller board, 9x9, and trying out the beginning of the game with random move selection gave me opportunity to see moves that were more reasonable than the end game portion that I started to map out. Even though there are more candidate moves possible at the beginning than at the end game, thus it look like more difficult problem, however, with many more "ok" moves that could be selected with some kind of random move selection, such as the stochastic beam search, I think it's possible to play much more reasonable moves. The typical characteristics of end game, which require exhaustive search to find the very few sometimes only one "right" moves made the task of coding impossible for me even though I thought I had pretty good idea of high level concepts and how to encode them. I could not successfully code the random move selection with candidate move pool into the program at the same time meeting the constraint of keeping temp value above 0.75. By switching numbers in the temp and also the value for the each position on board, it was possible to get very different playing characteristics.
However, if the program will ever to play in a reasonable level, it will need more constraints and/or it will need to somehow learn from its previous mistake by updating the temp value and/or the value of the each position on board. Even with that, it will need the exact or pretty close to exact evaluation of the board if it were to play the end game flawlessly.