Generalized
Separation of Style and Content on Nonlinear Manifolds with Application to
Human Motion Analysis
NSF CAREER Award number IIS- 0546372
PI: Ahmed Elgammal, Rutgers
University
Graduate Student Investigator:
Chan-Su Lee
Duration: January, 2006 _ Dec -2012
Project
Summary
The problem
of separation of style and content is an essential element of visual perception
and is a fundamental mystery of perception. For example, we are able to
recognize faces and actions under wide variability in the visual stimuli. While
the role of manifold representations is still unclear in perception, it is
clear that images of the same object lie on a low-dimensional manifold in the
visual space defined by the retinal array. On the other hand, neurophysiologists
have found that neural population firing is typically a function of a small
number of variables, which implies that population activities also lie on
low-dimensional manifolds.
This project
is focused on modeling the visual manifolds of biological motion. Despite the
high dimensionality of the configuration space, many human motions
intrinsically lie on low-dimensional manifolds. This is true for the kinematics
of the body, as well as for the observed motion through image sequences. Let us consider the observed motion.
For example, the silhouette (occluding contour) of a human walking or
performing a gesture is an example of a dynamic shape, where the shape deforms
over time based on the action being performed. These deformations are
restricted by the physical body and the temporal constraints posed by the
action being performed. Given the spatial and the temporal constraints, these
silhouettes, as points in a high-dimensional visual input space, are expected
to lie on a low-dimensional manifold. Intuitively, the gait is a
one-dimensional manifold that is embedded in a high-dimensional visual space.
Such a manifold can be twisted and even self-intersect in the high-dimensional
visual space. Similarly, the
appearance of a face performing expressions is an example of a dynamic
appearance that lies on a low-dimensional manifold in the visual input space.
In fact, if we consider certain classes of motion, such as gait, or a single
gesture, or a single facial expressions and if we factor out all other sources
of variability, each of these motions lie on a one-dimensional manifold, i.e.,
a trajectory in the visual input space. Such manifolds are nonlinear and
non-Euclidean.
Although the
intrinsic body configuration manifold might be very low in dimensionality, the
resulting visual manifold (in terms of shape and/or appearance) is challenging
to model, given the various aspects that affect the appearance. Examples of
such aspects include the body type (slim, big, tall etc.) of the person
performing the motion, clothing, viewpoint, and illumination. Such variability
makes the task of learning a visual manifold very challenging, because we are
dealing with data points that lie on multiple manifolds at the same time: body
configuration manifold, viewpoint manifold, body shape manifold, illumination
manifold, etc.
Achievements:
The main
contribution of this project is a computational framework for learning a
decomposable generative model that explicitly factorizes the intrinsic body
configuration (content) as a function of time from the appearance (style)
factors. The framework is based on decomposing the style parameters in the
space of nonlinear functions that maps between a unified representation of the
content manifold and style-dependent observations. Given a set of topologically equivalent manifolds, the Homeomorphic Manifold Analysis (HMA)
framework models the variation in their geometries in the space of functions
that maps between a topologically-equivalent common representation and each of
them. The common representation of the content manifold can be learned from the
data or can be enforced in a supervised way if the manifold topology is known.
The main assumption here is that the visual manifold is homeomorphic to the
unified content manifold representation, and that the mapping between that
unified representation and the visual space can be parameterized by different
style factors. [read
more…] [Sample Publications]
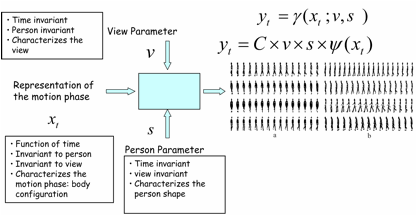
Example generative model for gait:
Multiple views and multiple people:
|
||||||||
|
|
|
|||||||
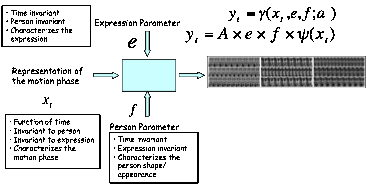
Example: Generative Model for Facial Expression: Different expressions, different people: |
||||||||
|
|
|
|||||||
|
|
||||||||
|
|
||||||||
Modeling
Multiple Continuous Manifolds: View, Posture, body style
|
||||||||
|
|
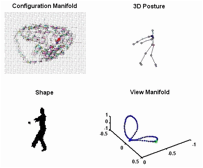
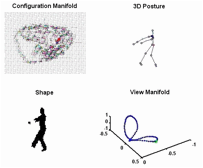
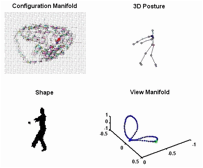
We consider modeling
data lying on multiple continuous manifolds. In particular, we model shape
manifold of a person performing a motion observed from different view points
along a view circle at fixed camera height. We introduce a model that ties
together the body configuration (kinematics) manifold and the visual manifold
(observations) in a way that facilitates tracking the 3D configuration with
continues relative view variability. The model exploits the low
dimensionality nature of both the body configuration manifold and the view
manifold where each of them is represented separately. - C-S. Lee and A. Elgammal “Coupled Visual and Kinematics Manifold Models for Human Motion
Analysis” International Journal on Computer Vision. Volume 87, Numbers
1-2, March 2010. C.-S. Lee and A. Elgammal Modeling View and Posture Manifold for
Tracking , International Conference on Computer Vision (ICCV), 2007. |
|||||||
|
Example
tracking of a ballet motion from multiple views: |
||||||||
|
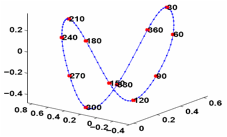
(a) Sampled shapes in different views
for ballet.____ _____(b) Embedded
kinematics manifold in 2D
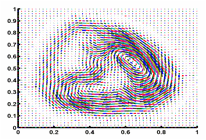
(c) View manifold embedded in the
kinematic manifold mapping space (d) Velocity
field value with interpolation.
(e) Test silhouette sequences
(f) Reconstruction of 3D body pose based on estimated body
configuration |
||||||||
|
|
||||||||
|
Demo Videos – a Generative
Model for a ballet dance routine: |
||||||||
|
|
||||||||
|
Fixing the body posture and
changing the viewpoint
|
Fixing the viewpoint and
changing the posture
|
|
||||||
|
Changing both the posture and
viewpoint
More demo views are
available here [click] |
||||||||
|
|
|
|||||||
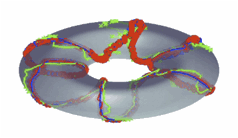
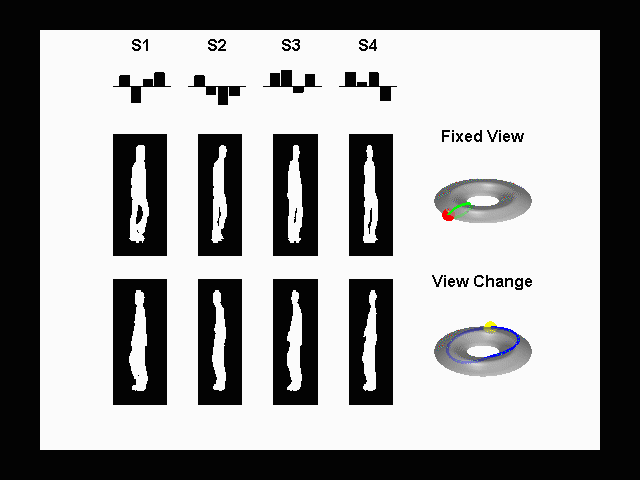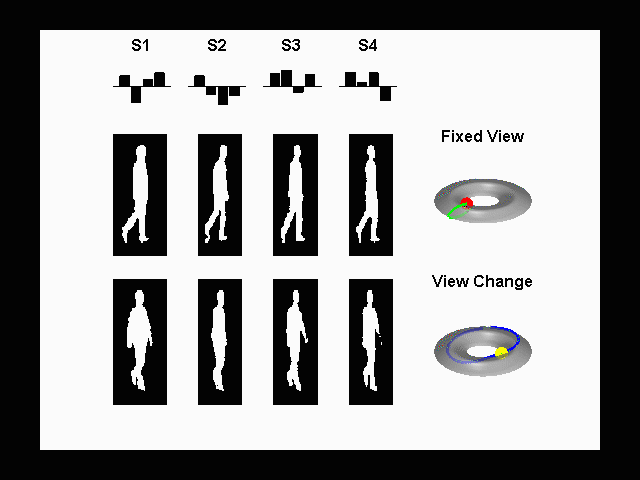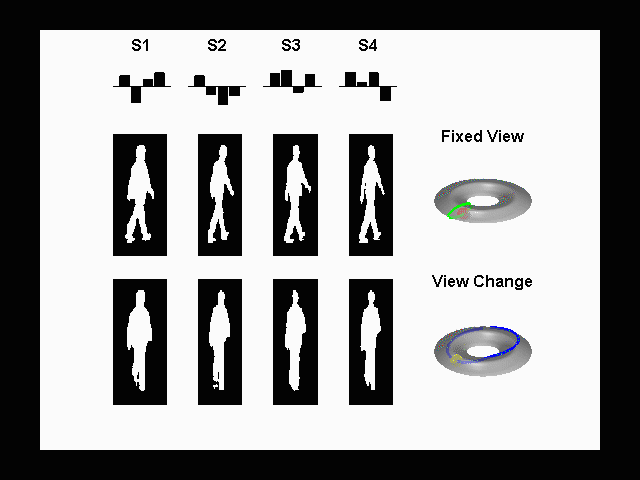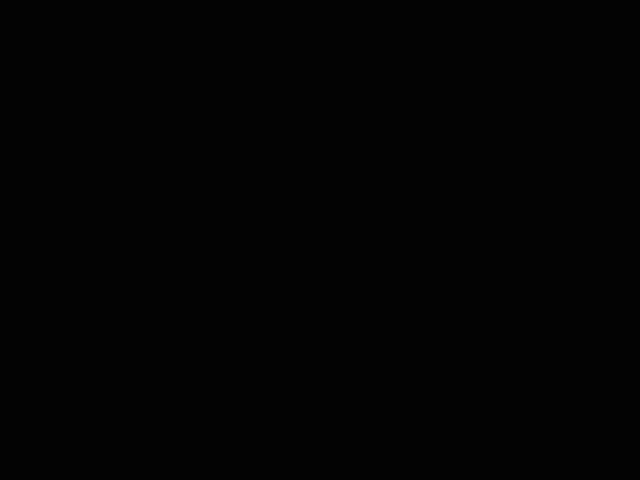
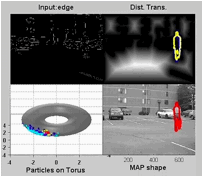
Joint Modeling
of Posture and View on a Torus: Tracking People on a Torus
|
||||||||
|
|
A
framework for monocular 3D kinematic posture tracking and viewpoint
estimation of periodic and quasi-periodic human motions from an uncalibrated
camera. Both the visual observation manifold and the kinematic manifold of
the motion are learnt using a joint representation. We showed that the visual
manifold of the observed shape of a human performing a periodic motion,
observed from different viewpoints, is topologically equivalent to a torus
manifold. The approach is based on the supervised learning of both the visual
and kinematic manifolds. Instead of learning an embedding of the manifold, we
learn the geometric deformation between an ideal manifold (conceptual
equivalent topological structure) and a twisted version of the manifold (the
data). Experimental results show accurate estimation of the 3D body posture
and the viewpoint from a single uncalibrated camera. - C-S. Lee and A.
Elgammal “Tracking People on a Torus”
IEEE transactions on Pattern Analysis and Machine Intelligence, March 2009 - C.-S. Lee and
A. Elgammal “Simultaneous
Inferring View and Body Pose Using Torus Manifolds” ICPR'06 |
|||||||
|
Demo
Videos: |
|
|||||||
|
|
|
|
|
|||||
|
|
||||||||
|
|
||||||||



 _
_
 _
_

Selected Publications:
C-S. Lee and A. Elgammal “Coupled Visual and Kinematics Manifold
Models for Human Motion Analysis” International Journal on Computer Vision.
Volume 87, Numbers 1-2, March 2010.
C-S.
Lee and A. Elgammal “Tracking People on a
Torus” IEEE transactions on Pattern Analysis and Machine Intelligence,
March 2009
C.-S. Lee and A. Elgammal Modeling View and Posture Manifold for
Tracking , International Conference on Computer Vision (ICCV), 2007.
A. Elgammal and C.-S. Lee “Nonlinear
Manifold Learning for Dynamic Shape and Dynamic Appearance” Computer Vision and Image Understanding
(CVIU) special issue on generative model based vision. April 2007
C.-S. Lee and A. Elgammal “Simultaneous Inferring View and Body
Pose Using Torus Manifolds” ICPR'06
A. Elgammal, C.-S. Lee “Separating Style and Content on a Nonlinear
Manifold” CVPR'04
A. Elgammal, C.-S. Lee “Inferring 3D Body Pose from Silhouettes
using Activity Manifold Learning” CVPR'04