Kafka
Distributed Streaming platform
Paul Krzyzanowski
April 15, 2021
Goal: Create a distributed messaging system to handle large-scale streams of messages.
Introduction
How can a cluster of computers handle the influx of never-ending streams of data, coming from multiple sources? This data may come from industrial sensors, IoT devices scattered around the world, or log files from tens of thousands of systems in a data center.
It’s easy enough to say that we can divide the work among multiple computers but how would we exactly do that?
Kafka
Kafka is an open-source high-performance, distributed, durable, fault-tolerant, publish-subscribe messaging system. We will cover every one of these points as we explore this system.
Kafka was created at LinkedIn around 2010 to track various events, such as page views, messages from the messaging system, and logs from various services.
It is used for moving messages streams around. These include data pipelines, alerts, logs, and various activities. With Kafka, one can collect these data streams for processing by frameworks such as Spark Streaming.
Publish-Subscribe Messaging
In a publish-subscribe messaging system, systems called publishers send streams of messages. These are the producers, since they produce messages. Another set of systems, called subscribers, read those messages. These are the consumers, since they consume the messages.
A messaging system, known as a message broker, is used to move data streams between applications. It provides a loose coupling between publishers and subscribers, or producers and consumers of data.
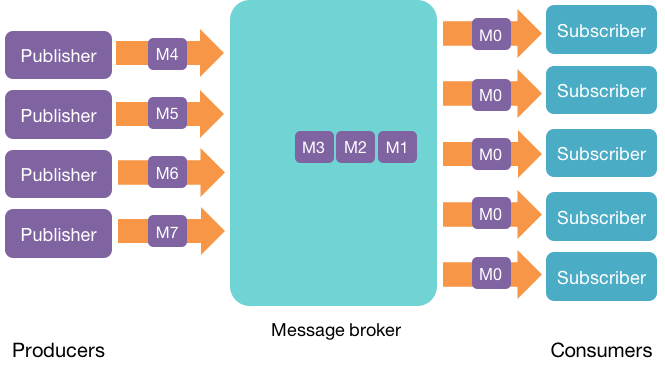
The message broker stores published messages in a queue and subscribers read them from the queue. Hence, subscribers and publishers do not have to be synchronized. This loose coupling allows subscribers and publishers to read and write at different rates.
The ability of the messaging system to store messages provides fault tolerance so messages don’t get lost between the time they are produced and the time they are consumed.
Topics
We can have many different message streams in our environment. For instance, system logs serve different purposes than temperature reports, which are likely to be processed by different software than the software that handles analytics data. Each stream is identified by a topic. Consumers subscribe to topics to receive messages produced for that topic.
A topic can be thought of as a feed of related data. Each message is associated with a topic. A topic can have zero, one, or many subscribers (consumers) that read data from it.
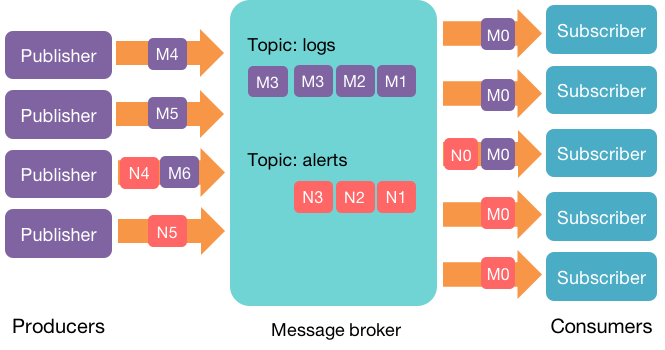
Kafka runs as a cluster on one or more servers. Each server in Kafka is called a broker1. A Kafka environment may have anywhere from one to thousands of brokers.
Kafka supports a publish-subscribe model that handles multiple message streams. These message streams are stored as a first-in-first-out (FIFO) queue in a fault-tolerant manner. Processes can read messages from streams at any time.
Kafka can be used as a component to feed data into real-time systems such as Spark Streaming or for batch processing by storing data into Amazon S3 or HDFS files for future data analysis by platforms like MapReduce or Spark.
Partitions
Each topic is managed as a partitioned log. It enables Kafka to scale.
In Kafka, a log is an ordered queue of message records. A partitioned log is a log that is broken up into multiple smaller logs, each of which is called a partition.
A partition is an ordered, immutable sequence of messages that is continually appended to. Each message contains a sequential ID number called the offset that uniquely identifies the message in the partition.
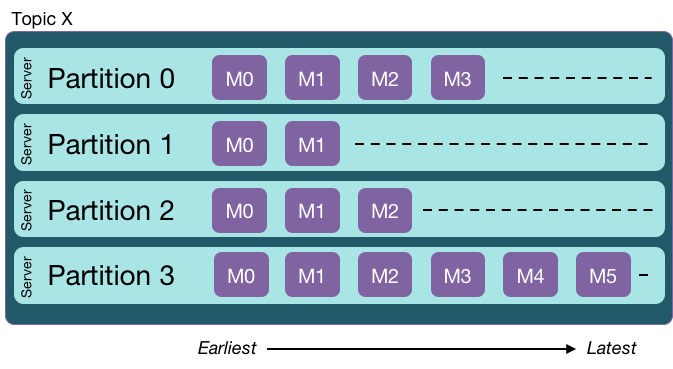
Partitions allow the log to scale beyond a single server. Each partition must fit on one of the servers that hosts it … but a topic can have multiple partitions and therefore handle an arbitrary amount of data. Each server manages a set of partitions belonging to different topics.
Fault tolerance
All messages in the log are durable, meaning they are written to disk. The messages persist for a configurable time period. After that time, they are discarded. Partitions can be replicated onto multiple servers for fault tolerance.
Each partition has one server that is elected to be the leader for that partition. There can be zero or more other servers that are followers for that partition. The amount of replication is a configurable parameter. The leader handles all read/write requests for the partition and is responsible for replicating messages to its followers. Only the leader communicates with clients. If the leader fails, one of the followers gets elected to be the new leader.
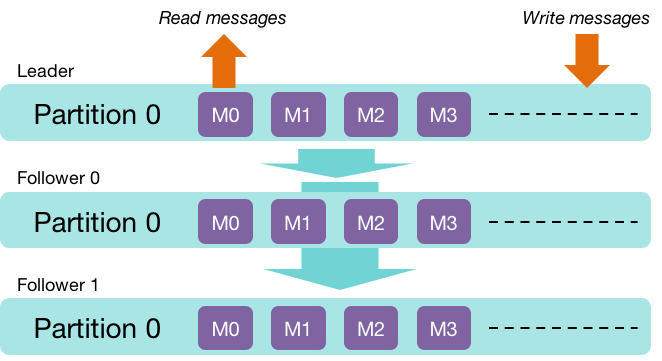
We need to consider the situation where a leader receives a message but dies before it is replicated to followers. In this case we have the danger of losing a message.
In a manner similar to Amazon Dynamo (although Dynamo is somewhat more flexible), a producer can choose the behavior: whether to receive an acknowledgment immediately once the broker receives the message or to wait until the message is replicated to all followers.
For load balancing, the Kafka framework tries to distribute leaders for different partitions among the available servers, so each server will be a leader for some partitions and a follower for others.
Scale
Kafka is designed to be highly scalable. This means:
- Being able to handle an increase in the volume of incoming messages from producers.
- Allowing consumers to grow to handle an increase in the volume or the processing complexity of messages.
- Being able to store large queues of messages.
The last of these, the ability to handle queues is addressed by breaking a topic into multiple partitions. A partition is limited to a single broker but many partitions can be managed my many systems.
Scaling - producers
Producers publish data to topics of their choice. Each publisher process is responsible for choosing which message goes to which partition. The simple algorithm is a round-robin distribution to balance the message load uniformly. Alternatively, programmers have the option to define their own partitioning function if they want to direct specific data within a topic to a certain partition.
More partitions in a topic allows a message stream to be distributed among more severs, enabling the cluster to sustain a heavier load of incoming data.
However, note that messages are only ordered on a per-partition basis. If message order is important, we can use a custom partitioning function or even force the use of just a single partition.
Scaling - consumers
A consumer process is part of a consumer group. A consumer group may have one or more consumers within it.
This allows you to distribute the processing of messages among multiple consumers. Each member of the consumer group gets a fair share of partitions for its subscribed topic.
Queuing vs. publish-subscribe
There are two common ways to handle messages: queuing and publish-subscribe.
With the queuing model, you have a pool of consumers that grab messages from a shared queue. Once a consumer grabs a message, it is out of the queue and the next consumer will get the next message.
This is a great model for distributing message processing among multiple consumers so that consumer load can be balanced.

The publish-subscribe model is one where all consumers that subscribe to a topic will get every message for that topic. This model allows multiple clients to get the same data but does not scale well.
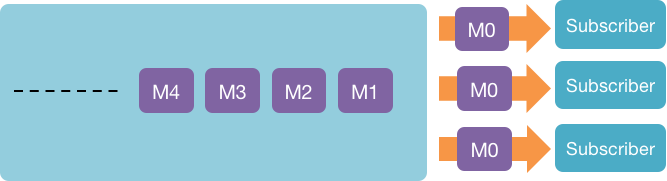
Kafka offers both of these models. By creating consumer groups, consumers can distribute their processing among a collection of processes. Each consumer group provides a publish-subscribe model, so consumers can join separate groups if they each need to receive the same set of messages for a topic.
Zookeeper
Kafka relies on Apache Zookeeper, which is Apache’s implementation of Chubby. Kafka uses zookeeper for getting heartbeats from brokers, leader election, replication settings, and tracking the members of the cluster. Producers contact Zookeeper to find partitions. Consumers contact Zookeeper to track the current index number of the next message in each partition.
Disks
Kafka writes its messages to the local disk on a partition server. Disks storage is important for durability - that the messages will not disappear if the system dies and restarts.
Disks are generally considered to be slow. We saw how Spark made a point of trying to keep RDDs cached in memory. However, there is a huge difference in disk performance between random block access and sequential access. The sequential nature of writing or reading logs enables disk operations can be thousands of times faster than random access.
For example, one measurement shows a RAID-5 disk can handle streaming writes at a rate of about 600 MB/s while random writes – those that involve seeking – perform at around 100 KB/s, over 6,000x slower. Kafka is carefully tuned to maximize streaming disk operations.
Summary
Kafka solved the problem of dealing with huge continuous streams of data.
Kafka solves the scaling problem of a messaging system by splitting a topic into multiple partitions across many systems. The basic abstraction of Kafka is a partitioned log.
It supports a single queue model with multiple readers by enabling consumer groups.
It supports a publish-subscribe model by allowing consumers to subscribe to topics for which they want to receive messages.
Message ordering is preserved only on a per-partition basis.
Kafka has proven itself in many places. It was initially created at LinkedIn as an open source project. It is commercially supported by Confluent and is now used by over 100,000 organizations. Some of these include:
- Activision: for gameplay events, diagnostics, and player experience improvements
- AirBnB: uses multiple Kafka clusters for analytics, change data capture and inter-service communication
- Tinder: for notifications, recommendations, analytics
- Pinterest: every click, resin, or photo enlargement results in messages through Kafka; also real-time ad budget calculations
- Uber: for matching drivers and customers, sending ETA calculations, and audit data
- Netflix: handles over 1.4 trillion of messages per day
- LinkedIn: handles 7 trillion messages per day over 100,000 topics across 7 million partitions stored on over 4,000 brokers (servers).
References
Apache Kafka, kafka.apache.org.
Have Klaskowski, The Internals of Apache Kafka, GitBook, February 2020.
Daniel Gutierrez, A Brief History of Kafka, LinkedIn’s Messaging Platform, inside BIGDATA, April 28, 2016.
Jean-Paul Azar, What is Kafka? Everything You Need to Know, DZone, August 9, 2017.
What is Apache Kafka?, May 10, 2017.
Maria Wachal, What is Apache Kafka and what are Kafka use cases?, Medium, January 15, 2020.
Michael Matloka, Who and why uses Apache Kafka?, January 8, 2020.
Jon Lee, How LinkedIn customizes Apache Kafka for 7 trillion messages per da, October 8, 2019
Kafka Architecture, Cloudurable blog.
Yaroslav Tkachenko, Streaming Audio: a Confluent podcast about Apache Kafka, Confluent podcast, January 27, 2020.
-
Note that in most messaging systems, the entire system is referred to as a broker. In Kafka, it refers to a single server that manages one or more partitions. ↩︎